AI 시대, 데이터 표현의 두 축: 임베딩과 그래프
들어가면서: AI는 모든 것을 알고 있을까?
최근 대규모 언어 모델(LLM)의 발전은 놀랍습니다. AI가 세상의 지식을 모두 꿰뚫고 있는 것처럼 느껴질 때도 있죠. 하지만 실제로는 그렇지 않습니다. AI의 답변 품질은 모델 자체의 언어 능력만이 아니라, 외부에서 얼마나 정확하고 풍부한 맥락을 찾아 제공하느냐에 크게 좌우됩니다. 답변 품질이 곧 검색 품질에 달려 있는 셈이고, 이 점은 RAG(Retrieval-Augmented Generation) 시스템에서 특히 두드러집니다.
키워드 검색의 한계: ‘의미’를 놓치다
우리가 오랫동안 써온 전통적인 검색은 대체로 키워드(Keyword) 기반입니다. 특정 단어가 문서에 들어 있는지를 따져 결과를 돌려주죠. 하지만 이 방식에는 뚜렷한 한계가 있습니다.
예를 들어 “자율주행차” 정보를 찾을 때, “무인 자동차”가 들어간 문서는 검색되지 않을 수 있습니다. 두 단어는 의미가 매우 비슷한데도 키워드만으로는 그 유사성을 잡아내기 어렵기 때문입니다. 키워드 검색은 단어의 표면적 일치에 매달리는 탓에 의미적 유사성(Semantic Similarity)을 파악하는 데 약합니다.
임베딩(Embedding): 의미적 위치를 만든다
이 한계를 넘기 위해 등장한 개념이 임베딩(Embedding)입니다. 임베딩은 단어와 문장, 문서 같은 텍스트를 수치화된 벡터(Numerical Vector)로 바꾸는 기술입니다. 이 벡터 공간에서는 의미가 비슷한 데이터일수록 서로 가까운 곳에 놓입니다.
임베딩은 이렇게 의미적 위치를 만듭니다. “자율주행차”와 “무인 자동차”는 다른 단어지만 임베딩 공간에서는 매우 가까운 벡터 값을 갖죠. 그래서 “자율주행차”를 검색해도 “무인 자동차” 정보까지 함께 찾아냅니다. 임베딩의 핵심은 “비슷한 것 찾기”에 강하다는 점입니다.
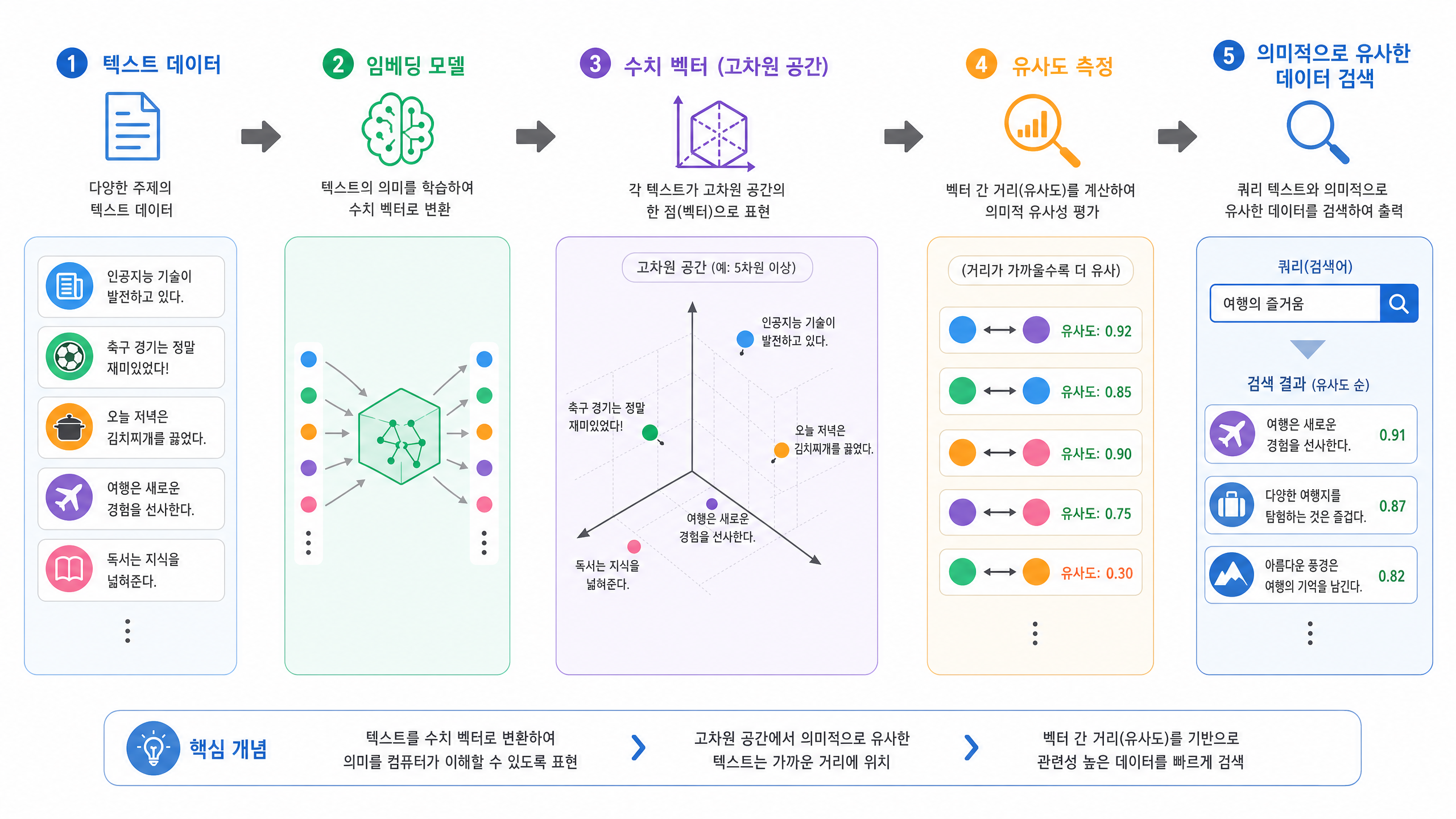
임베딩의 한계: 관계 추론에는 약하다
임베딩은 의미적 유사성 파악에는 탁월하지만 모든 문제를 풀어 주지는 않습니다. 특히 데이터 사이의 복잡한 관계를 추론하거나 경로를 탐색하는 일에는 한계가 있습니다.
예를 들어 “A라는 인물이 B라는 회사에 근무하며, B회사는 C라는 기술을 사용하고, C기술은 D라는 특허와 관련이 있다”와 같은 관계는 임베딩만으로 파악하기 어렵습니다. 임베딩은 각 개체(인물, 회사, 기술, 특허)의 의미적 유사성은 잘 나타내지만, 이들을 잇는 명시적인 연결 고리(Explicit Relationship)나 관계의 종류까지 곧바로 드러내지는 못합니다. ‘무엇이 비슷한가’는 잘 알아도 ‘무엇이 어떻게 연결되어 있는가’는 설명하기 어려운 것이죠.
그래프(Graph): 관계 지도를 만든다
여기서 그래프(Graph)의 역할이 커집니다. 그래프는 노드(Node)와 엣지(Edge)로 이뤄져 데이터 사이의 관계를 직접 표현하는 구조입니다.
- 노드(Node): 개체(Entity)를 나타냅니다. (예: 사람, 회사, 기술, 특허)
- 엣지(Edge): 노드 간의 관계(Relationship)를 나타냅니다. (예: 근무한다, 사용한다, 관련 있다)
그래프는 이렇게 관계 지도를 만듭니다. 그래프를 쓰면 “A는 B에 근무한다”, “B는 C를 사용한다” 같은 관계를 명시적으로 담고, 그 관계를 따라가며 정보를 탐색할 수 있습니다. 관계 추론이나 경로 탐색에 특히 강한 방식이죠.
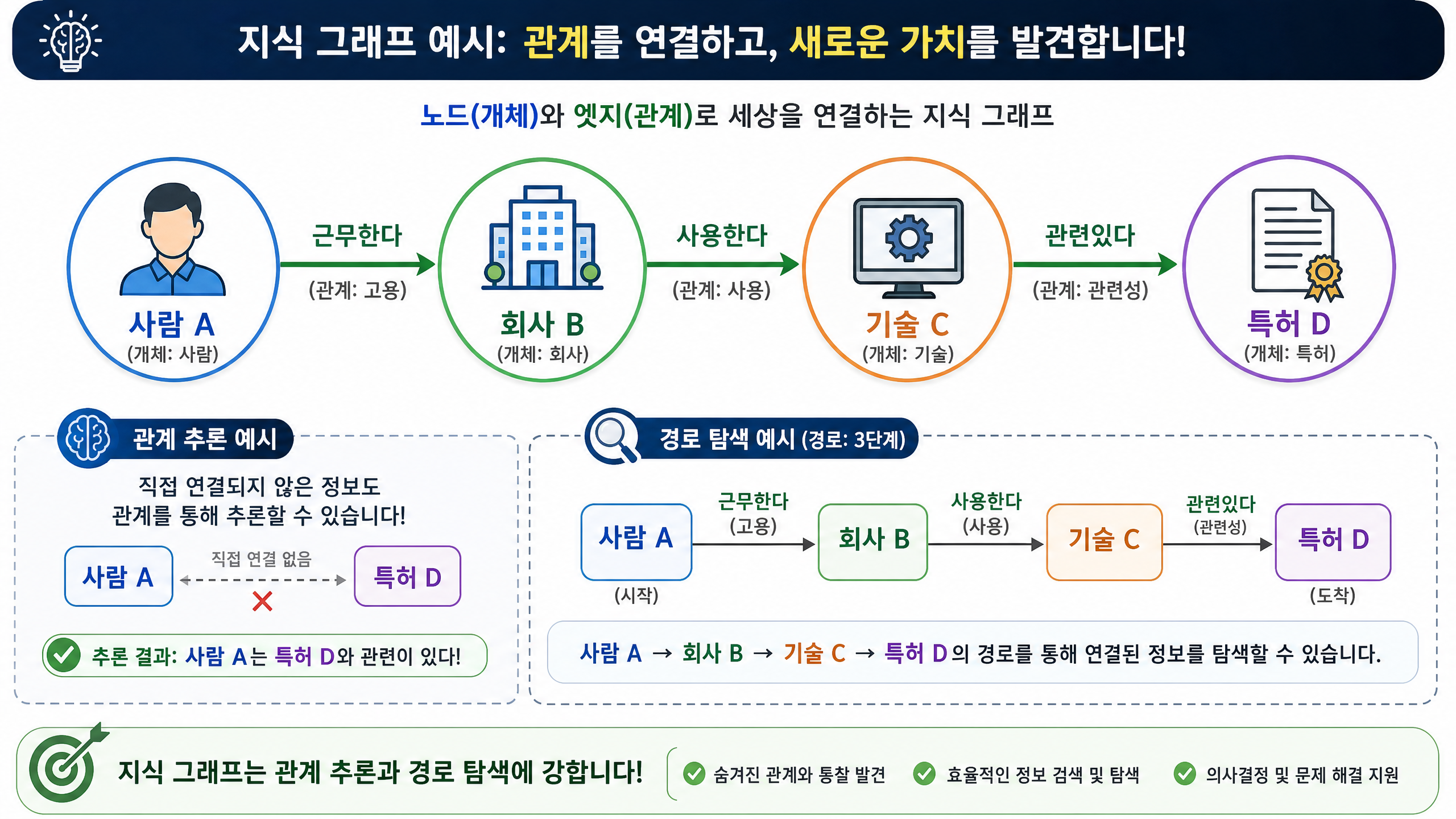
임베딩과 그래프의 차이: 비슷한 것 vs 연결된 것
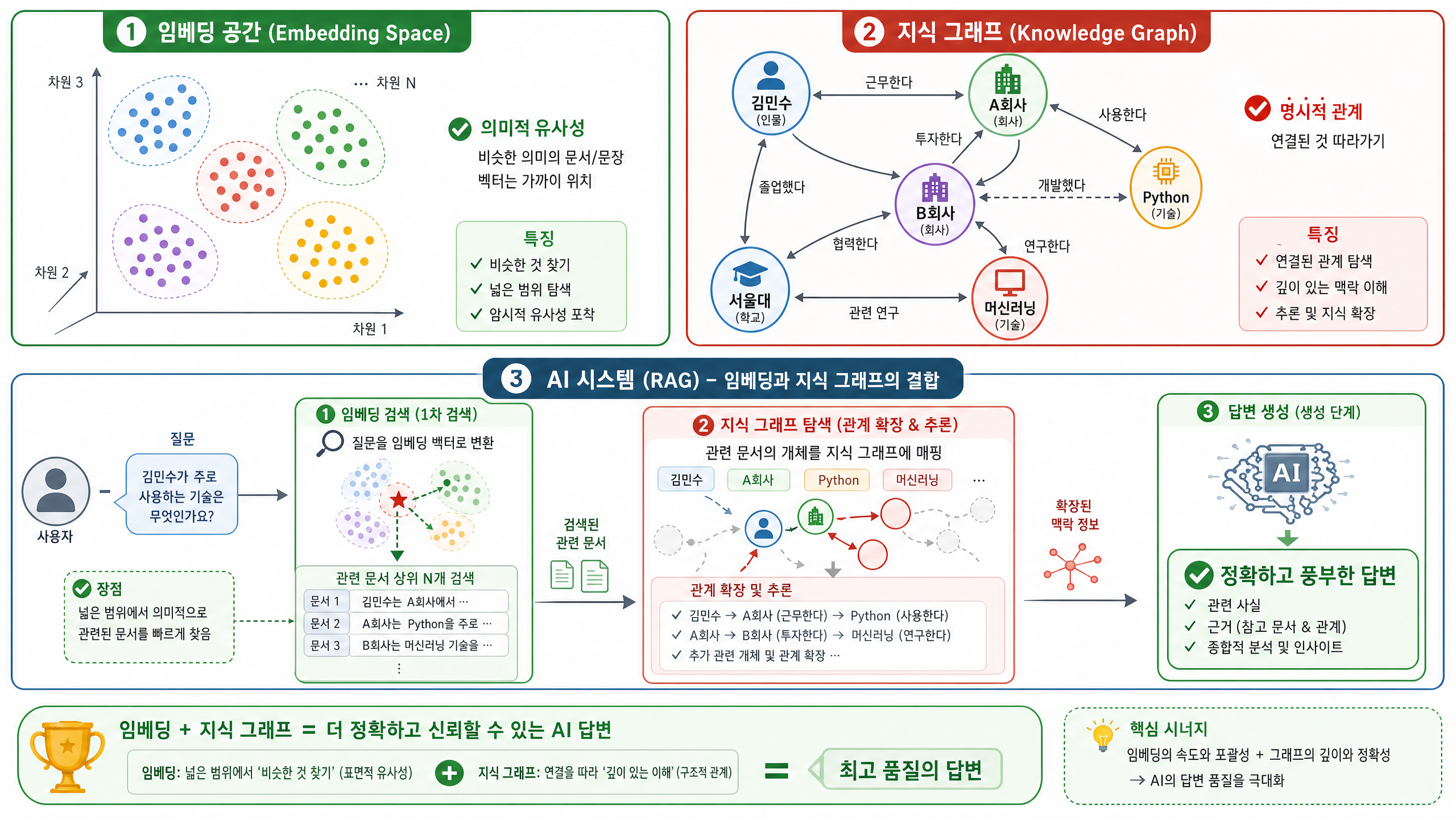
정리하면 임베딩과 그래프는 데이터를 표현하는 방식도, 강점도 뚜렷이 다릅니다.
| 특징 | 임베딩(Embedding) | 그래프(Graph) |
|---|---|---|
| 데이터 표현 | 고차원 벡터 공간의 점 | 노드(개체)와 엣지(관계) |
| 강점 | 의미적 유사성 파악, 비슷한 것 찾기 | 명시적 관계 표현, 관계 추론 및 경로 탐색 |
| 핵심 표현 | 의미적 위치를 만든다 | 관계 지도를 만든다 |
| 활용 예시 | 시맨틱 검색, 추천 시스템, 텍스트 분류 | 지식 그래프, 소셜 네트워크 분석, 사기 탐지 |
임베딩은 비슷한 것을 찾고, 그래프는 연결된 것을 따라갑니다. 둘은 서로를 보완하는 사이입니다.
실제 AI 시스템에서의 결합: RAG, AI Agent, Knowledge Graph
그렇다면 RAG(Retrieval-Augmented Generation)나 AI Agent처럼 복잡한 시스템에서는 이 둘을 어떻게 쓸 수 있을까요? 대개는 둘을 함께 쓰게 됩니다.
- 임베딩 기반의 1차 검색: 사용자의 질문이 들어오면 먼저 임베딩 시맨틱 검색으로 질문과 의미가 비슷한 문서나 지식 조각을 빠르게 찾아냅니다. 넓은 범위에서 관련성 높은 정보를 걸러 내는 데 효과적이죠.
- 그래프 기반의 관계 확장 및 추론: 1차 검색으로 얻은 정보를 발판 삼아 지식 그래프(Knowledge Graph)를 탐색해, 그 정보와 연결된 다른 개체나 관계를 찾아냅니다. 예컨대 특정 문서에 언급된 인물이나 기술이 그래프 안에서 어떤 정보와 이어지는지 추론해 맥락을 넓히는 식입니다. 이렇게 하면 AI가 더 깊고 정확한 답변을 내놓는 데 필요한 배경 지식이 채워집니다.
- 메타데이터 활용: 여기에 생성일, 작성자, 중요도 같은 메타데이터까지 함께 쓰면 검색과 추론의 정확도를 한층 끌어올릴 수 있습니다.
이런 접근은 LLM이 학습된 지식에만 기대지 않고 외부의 최신 정보나 특정 도메인의 전문 지식까지 끌어 쓰도록 돕습니다. AI 에이전트가 복잡한 작업을 해내려면 안정적이고 예측 가능한 실행 환경(Harness)이 필요하듯 1, AI 시스템의 답변 품질을 높이려면 데이터를 어떻게 표현하고 검색할지가 무척 중요합니다.
오늘의 마무리: LLM 성능 너머의 데이터 표현
이번 학습에서 저는 “LLM 성능”만큼이나 데이터 표현 방식도 중요하다는 점을 배웠습니다. 아무리 강력한 LLM이라도 입력 데이터가 불완전하거나 비효율적으로 표현돼 있으면 제 잠재력을 온전히 내기 어렵습니다. 특히 RAG, AI Agent, Knowledge Graph, Semantic Search 같은 최신 AI 시스템을 만들 때는 데이터의 내용만이 아니라 그 데이터를 어떻게 저장하고 검색하며 관계를 탐색할지까지 깊이 고민해야 합니다.
결국 AI 답변 품질은 검색 품질에 크게 좌우됩니다. 앞으로 AI 시스템을 설계할 때는 데이터의 의미적 유사성과 관계적 연결성을 함께 살피는 표현 방식에 더 마음을 쓰려 합니다. “아 왜 AI 시스템에서 데이터 표현 방식이 중요한지 감이 온다”는 느낌을 받으셨다면, 이 글은 제 몫을 한 셈입니다.
References
- RAG (Retrieval-Augmented Generation) Explained
- What is a Knowledge Graph?
- Semantic Search: What it is and why it matters
이전에 AI 에이전트의 Harness(하네스)에 대한 기술적 고찰에서 AI 에이전트의 안정적인 실행 환경의 중요성에 대해 다룬 바 있습니다. ↩︎