Spring AI 실전: Tool Calling 설계와 멀티 모델 활용 전략
1. Spring AI 실습: 이론을 코드로 확인하는 시간
지난 Spring AI로 AI 앱 개발 시작하기: ChatClient와 Structured Output 포스팅에서 Spring AI의 기본적인 개념과 ChatClient, Structured Output의 중요성에 대해 이론적으로 살펴보았습니다. 오늘은 그 이론을 실제 multimodal-spring-ai-boot4 프로젝트 안에서 코드로 확인해 보겠습니다. 특히 Tool Calling 설계와 멀티 모델 활용 전략을 깊이 있게 들여다보겠습니다.
AI 프로젝트는 AI에게 일을 한 번에 맡기지 않습니다. 복잡한 비즈니스 로직을 거대한 함수 하나로 처리하지 않고 여러 작은 함수와 클래스로 나눠 관리하는 것과 같은 이치입니다. AI에게 “영수증 이미지 + 사용 목적 -> AI야, 이거 경비 처리 가능한지 한 번에 판단해줘 -> 최종 답변”과 같이 한 번에 모든 것을 맡기는 방식은 다음과 같은 문제를 야기합니다.
- 불투명성: 모델이 영수증 금액을 잘못 읽어도 중간에서 확인하기 어렵습니다.
- 신뢰성 부족: 회사 규정을 모델이 추측할 수 있으며, 어떤 근거로 승인/반려했는지 추적하기 어렵습니다.
- 데이터 계약 부재: 후속 로직에서 사용할 데이터 계약이 없어 통합이 어렵습니다.
이런 문제를 피하려면 AI 기능을 단계별로 나눠 설계해야 합니다.
AI 기능 단계별 분해 (영수증 처리 예시)
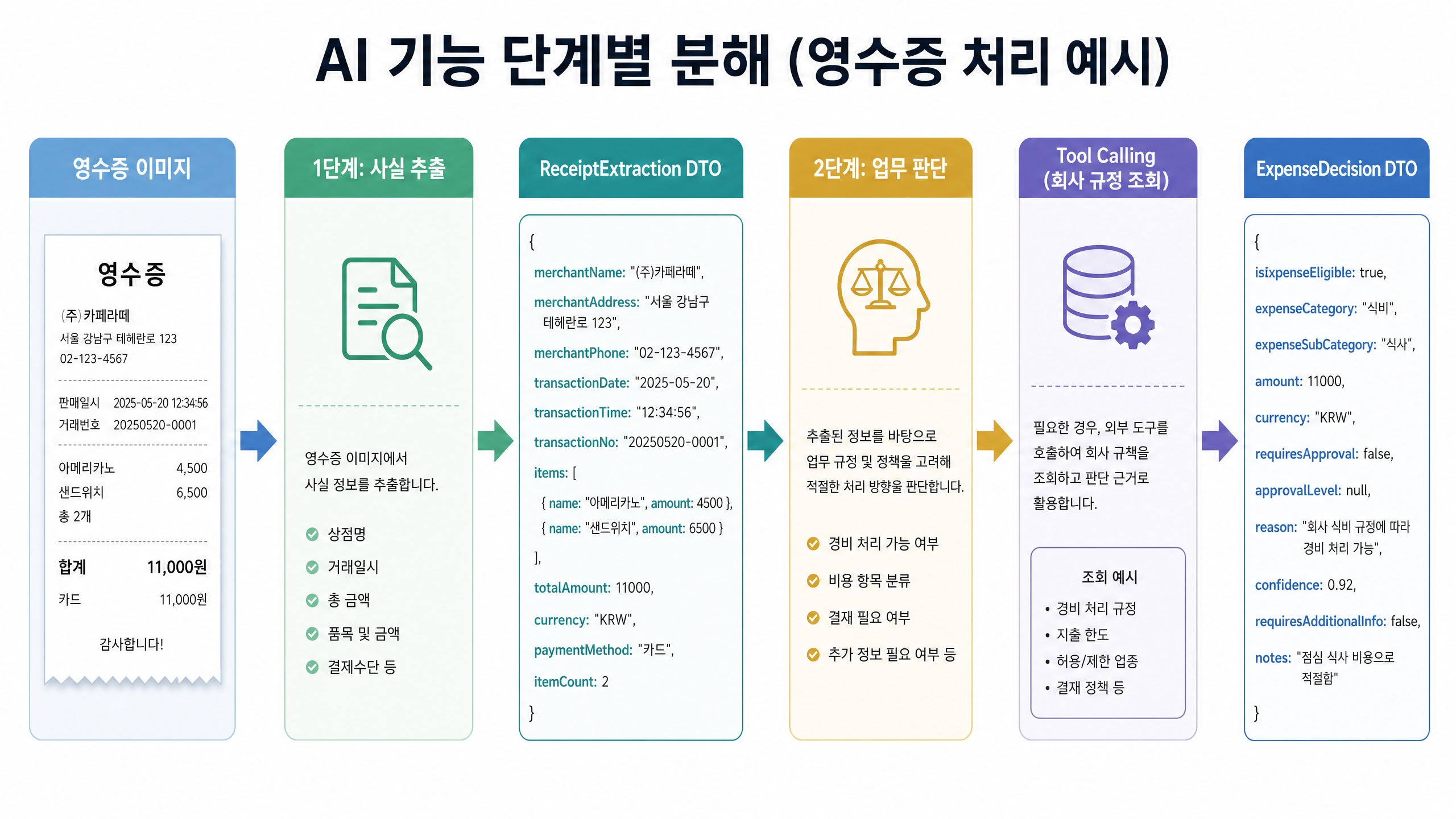
- 1단계: 영수증 이미지 읽기
- 입력: 영수증 이미지
- 출력:
ReceiptExtractionDTO (구조화된 영수증 데이터)
- 2단계: DTO + 사용 목적으로 경비 카테고리 판단
- 입력:
ReceiptExtractionDTO, 사용 목적 - 과정: 필요한 회사 규정
Tool Calling - 출력:
ExpenseDecisionDTO (경비 처리 판단 결과)
- 입력:
이렇게 단계를 나누면 AI를 더 잘 통제하고, 각 단계의 책임을 명확히 할 수 있습니다.
| 설계 포인트 | 이유 |
|---|---|
| 먼저 추출하고, 나중에 판단한다 | 읽기 오류와 판단 오류를 분리하여 디버깅 및 개선 용이 |
| 중간 결과를 DTO로 만든다 | 후속 로직과 검증이 가능하며, 데이터 계약을 명확히 함 |
| 회사 규정은 Tool로 조회한다 | 모델이 내부 규정을 추측하지 않게 하고, 실제 데이터를 기반으로 판단하게 함 |
| 최종 판단도 DTO로 받는다 | API 응답, 저장, 검토 흐름에 연결 가능하며, 구조화된 데이터 활용 |
| 로그를 남긴다 | 모델 호출과 도구 호출이 실제로 일어났는지 확인하여 관찰 가능성 확보 |
오늘의 핵심 메시지는 이 세 문장으로 요약할 수 있습니다.
AI에게 한 번에 다 맡기지 않는다. 중간 결과를 DTO로 만든다. 필요한 외부 지식은 Tool로 조회한다.
2. Mock 모드로 프로젝트 감 잡기
실제 AI API 호출은 네트워크 상태나 API 키 문제 등으로 불안정할 수 있습니다. multimodal-spring-ai-boot4 프로젝트에는 mock 프로필이 있어, 실제 OpenAI 호출 없이 백엔드 API의 계약과 실습 흐름을 안정적으로 확인할 수 있습니다.
Mock 모드에서 확인할 수 있는 것:
- 서버가 정상적으로 구동되는지
- HTTP 요청이 올바르게 처리되는지
- 파일 업로드가 제대로 동작하는지
- API 응답 모양(
receipt,decision등)이 예상과 일치하는지
핵심: Mock 모드는 AI 성능을 보는 모드가 아니라, 백엔드 API 계약과 실습 흐름을 먼저 안정적으로 확인하는 모드입니다.
Mock 모드에서 오해하지 말 것
Mock 모드에서는 Tool Calling이 실제로 일어나지 않습니다. 즉, check-expense API를 호출해도 모델이 도구를 선택하고 호출하는 실제 과정은 볼 수 없습니다. 실제 Tool Calling의 동작을 확인하려면 OpenAI 모델 모드로 실행해야 합니다.
3. Tool Calling: AI가 외부 도구를 사용하는 방법
POST /api/multimodal/check-expense API는 겉으로는 하나의 요청처럼 보이지만 내부적으로는 AI 호출이 두 번 일어나는 복합적인 과정입니다.
- 첫 번째 AI 호출: 영수증 이미지와 추출 프롬프트를 통해
ReceiptExtractionDTO를 생성합니다. (보이는 값을 읽는 일) - 두 번째 AI 호출:
ReceiptExtractionDTO, 사용 목적, 그리고 사용 가능한 도구 목록을 바탕으로 모델이 필요한 도구를 호출하여ExpenseDecisionDTO를 생성합니다. (읽은 값을 기준으로 업무 판단을 하는 일)
AI 호출을 두 번으로 나누는 이유는 각 단계의 책임을 분리해 디버깅을 쉽게 하고 오류의 원인을 명확히 파악하기 위해서입니다.
Spring AI Tool Calling 동작 방식
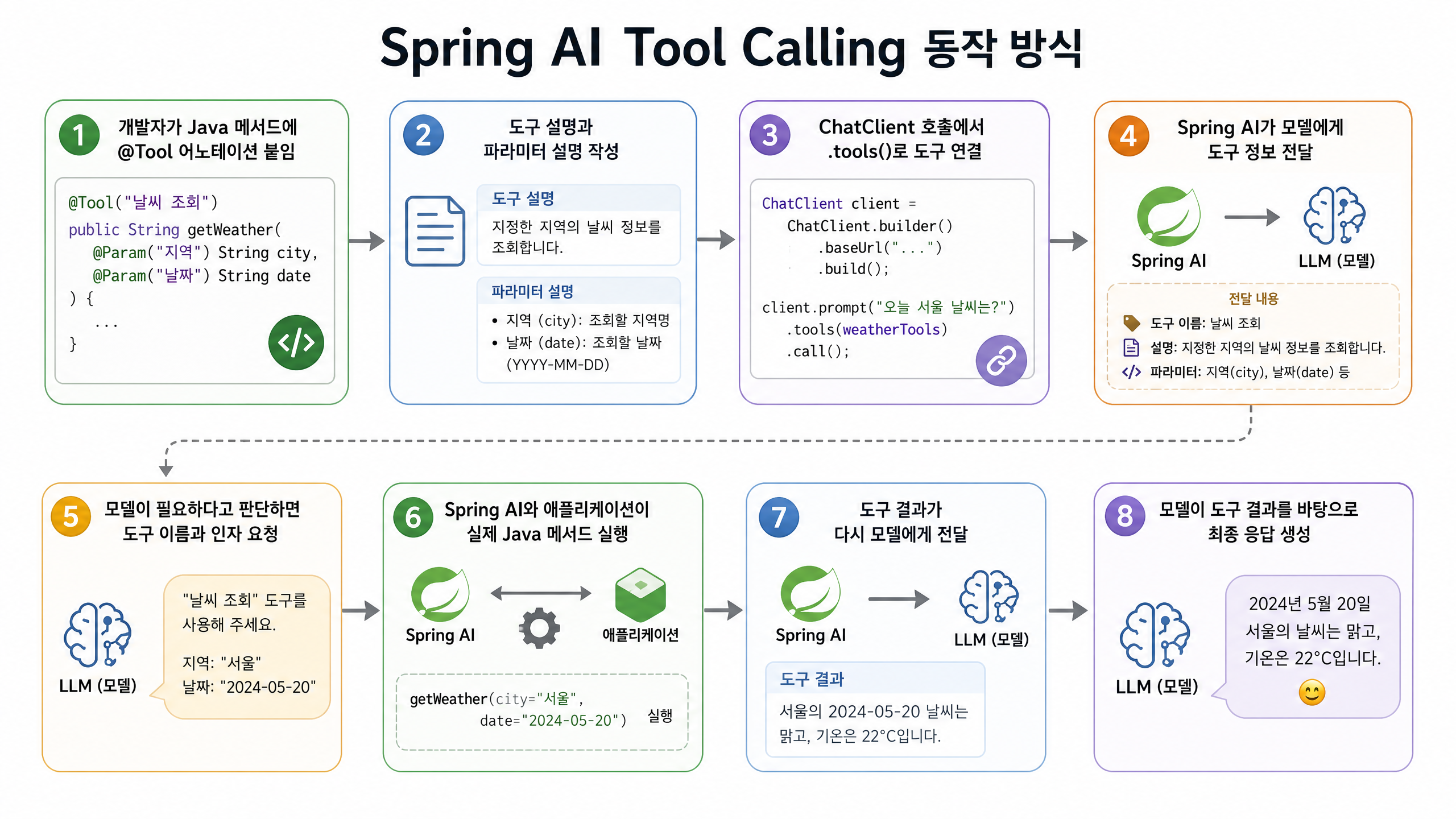
Spring AI에서 Tool Calling은 다음과 같은 흐름으로 동작합니다.
- 도구 정의: 개발자가 Java 메서드에
@Tool어노테이션을 붙여 도구를 정의하고, 도구 설명과 파라미터 설명을 구체적으로 작성합니다. - 도구 연결: 특정
ChatClient호출에서.tools(expensePolicyTools)와 같이 도구를 연결합니다. - 모델에게 도구 정보 전달: Spring AI는 모델에게 “이번 요청에서 사용할 수 있는 도구” 정보를 함께 보냅니다.
- 모델의 도구 호출 요청: 모델은 대화의 맥락을 분석하여 필요하다고 판단하면 도구 이름과 인자를 요청합니다.
- 애플리케이션의 도구 실행: Spring AI와 애플리케이션이 등록된 Java 메서드를 실제로 실행합니다.
- 도구 결과 전달: 실행된 도구의 결과가 다시 모델에게 전달됩니다.
- 최종 응답 생성: 모델은 도구 결과를 바탕으로 최종 응답을 만듭니다.
| 구분 | 의미 |
|---|---|
| 모델의 도구 호출 요청 | 모델이 “이 도구를 이 인자로 호출하면 좋겠다”고 판단 |
| 애플리케이션의 도구 실행 | Spring AI가 등록된 Java 메서드를 실제로 실행 |
Tool Calling 설계 팁
Tool Calling을 효과적으로 활용하기 위한 몇 가지 팁은 다음과 같습니다.
| 팁 | 이유 |
|---|---|
| 도구 설명은 구체적으로 쓴다 | 모델이 언제 어떤 도구를 써야 하는지 정확히 판단할 수 있도록 돕기 위함 |
| 파라미터 설명도 구체적으로 쓴다 | 잘못된 인자로 도구가 호출되는 일을 줄이고, 모델이 올바른 인자를 추출하도록 유도 |
| 도구는 필요한 요청에만 연결한다 | 모든 AI 요청에 불필요한 권한을 열어두지 않고, 보안 및 효율성을 높이기 위함 |
| 처음에는 읽기 전용 도구부터 만든다 | 삭제, 결제, 수정과 같은 쓰기 작업 도구는 위험도가 높으므로 신중하게 접근 |
| 도구 호출 로그를 남긴다 | 실제 호출 여부와 인자를 확인하여 디버깅 및 감사(Audit)에 활용 |
| 도구 결과를 최종 판단의 근거로 요구한다 | 모델이 도구 결과 없이 추측(Hallucination)하지 않도록 강제하여 신뢰성 확보 |
오늘 프로젝트에서는 defaultTools가 아니라 요청 안에서 .tools(expensePolicyTools)를 사용합니다. 모든 AI 요청에 도구를 열어두지 않고 경비 검토 요청에서만 경비 규정 도구를 제공해 권한을 최소화하는 방식입니다.
4. 한 애플리케이션 안에서 여러 모델을 동시에 쓰는 방식
실제 AI 애플리케이션에서는 하나의 AI 모델만 사용하기보다는, 각 작업의 특성에 맞는 여러 모델을 조합하여 사용하는 경우가 많습니다. 예를 들어, 이미지 추출에는 멀티모달에 강한 모델을, 긴 정책 판단에는 문맥 유지가 좋은 모델을, Tool Calling에는 도구 호출이 안정적인 모델을 쓰는 식입니다.

Spring AI는 이러한 멀티 모델 전략을 유연하게 지원합니다. build.gradle에 필요한 모델 스타터를 추가하고, application.yml에서 각 모델의 API 키와 옵션을 설정한 후, @Configuration 클래스에서 각 모델별 ChatClient Bean을 생성하여 @Qualifier로 주입받아 사용하면 됩니다.
1
2
3
4
5
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
implementation 'org.springframework.ai:spring-ai-starter-model-anthropic'
implementation 'org.springframework.ai:spring-ai-starter-model-google-genai'
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
spring:
ai:
chat:
client:
enabled: false # 기본 ChatClient 비활성화
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4o
anthropic:
api-key: ${ANTHROPIC_API_KEY}
chat:
options:
model: claude-sonnet-4-5
google:
genai:
api-key: ${GEMINI_API_KEY}
chat:
options:
model: gemini-2.0-flash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Configuration
public class AiClientConfig {
@Bean
ChatClient openAiChatClient(OpenAiChatModel model) {
return ChatClient.create(model);
}
@Bean
ChatClient anthropicChatClient(AnthropicChatModel model) {
return ChatClient.create(model);
}
@Bean
ChatClient geminiChatClient(GoogleGenAiChatModel model) {
return ChatClient.create(model);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class ExpenseReviewService {
private final ChatClient gemini;
private final ChatClient claude;
private final ChatClient openai;
public ExpenseReviewService(
@Qualifier("geminiChatClient") ChatClient gemini,
@Qualifier("anthropicChatClient") ChatClient claude,
@Qualifier("openAiChatClient") ChatClient openai
) {
this.gemini = gemini;
this.claude = claude;
this.openai = openai;
}
// ... 비즈니스 로직에서 각 ChatClient 활용
}
서비스 코드는 특정 provider 이름보다 geminiChatClient, anthropicChatClient와 같이 역할에 맞는 이름으로 ChatClient를 주입받아 사용하는 것이 좋습니다. 이렇게 하면 코드의 가독성과 유지보수성이 높아집니다.
5. 오늘의 정리!
이번 실습에서 다시 확인한 것은 AI 백엔드 개발의 핵심이 단순히 모델이 똑똑하다는 사실에 있지 않다는 점입니다. 핵심은 모델을 우리 서비스의 책임, 데이터 계약, 보안 경계, 관찰 가능성 안에 넣을 수 있느냐입니다.
Learned (배운 점)
- AI에게 한 번에 모든 것을 맡기지 않는다: 복잡한 AI 기능을 단계별로 분해하고, 각 단계의 책임을 명확히 하는 것이 중요하다.
- 중간 결과는 DTO로:
Structured Output을 통해 LLM의 응답을 구조화된 데이터로 받아 후속 로직의 안정성과 검증 가능성을 높인다. - 외부 지식은 Tool로 조회: LLM이 모르는 도메인 특화 지식이나 실시간 정보는
Tool Calling을 통해 외부 시스템에서 안전하게 조회하도록 설계한다. - Tool Calling은 자동화의 시작이자 권한: 도구는 필요한 요청에만 연결하고, 읽기 전용 도구부터 시작하여 위험도를 관리하는 것이 중요하다.
- 로그는 AI 기능의 관찰 창: 모델 호출, 도구 호출, 토큰 사용량 등을 로그로 기록하여 AI 기능의 내부 동작을 투명하게 관찰하는 습관이 필요하다.
- 멀티 모델 활용 전략: 각 작업의 특성(이미지 추출, 긴 정책 판단, Tool Calling 안정성 등)에 맞는 최적의 AI 모델을 배치하여 애플리케이션의 성능과 신뢰성을 극대화할 수 있다.