MySQL 인덱스, 무작정 추가하기 전에 알아야 할 것들
들어가면서
백엔드 개발을 하다 보면 “쿼리가 느린데 인덱스 하나 걸어보죠”라는 말을 자주 듣게 됩니다. 하지만 인덱스를 추가한다고 해서 모든 문제가 해결되는 것은 아닙니다. 오히려 잘못 설계된 인덱스는 데이터 삽입이나 수정 성능을 떨어뜨리고 관리 비용만 높이기도 합니다.
처음 인덱스를 접했을 때는 단순히 ‘빠른 검색을 위한 사전’ 정도로만 생각했습니다. 하지만 실무에서 다양한 쿼리 성능 문제를 마주하며, 인덱스는 개발자가 지정하는 명령이 아니라 DB 옵티마이저에게 제공하는 힌트에 가깝다는 사실을 깨달았습니다. 오늘은 초보 백엔드 개발자의 시선에서 인덱스를 언제 추가해야 하고, EXPLAIN으로 무엇을 확인해야 하는지 정리해 보려고 합니다.
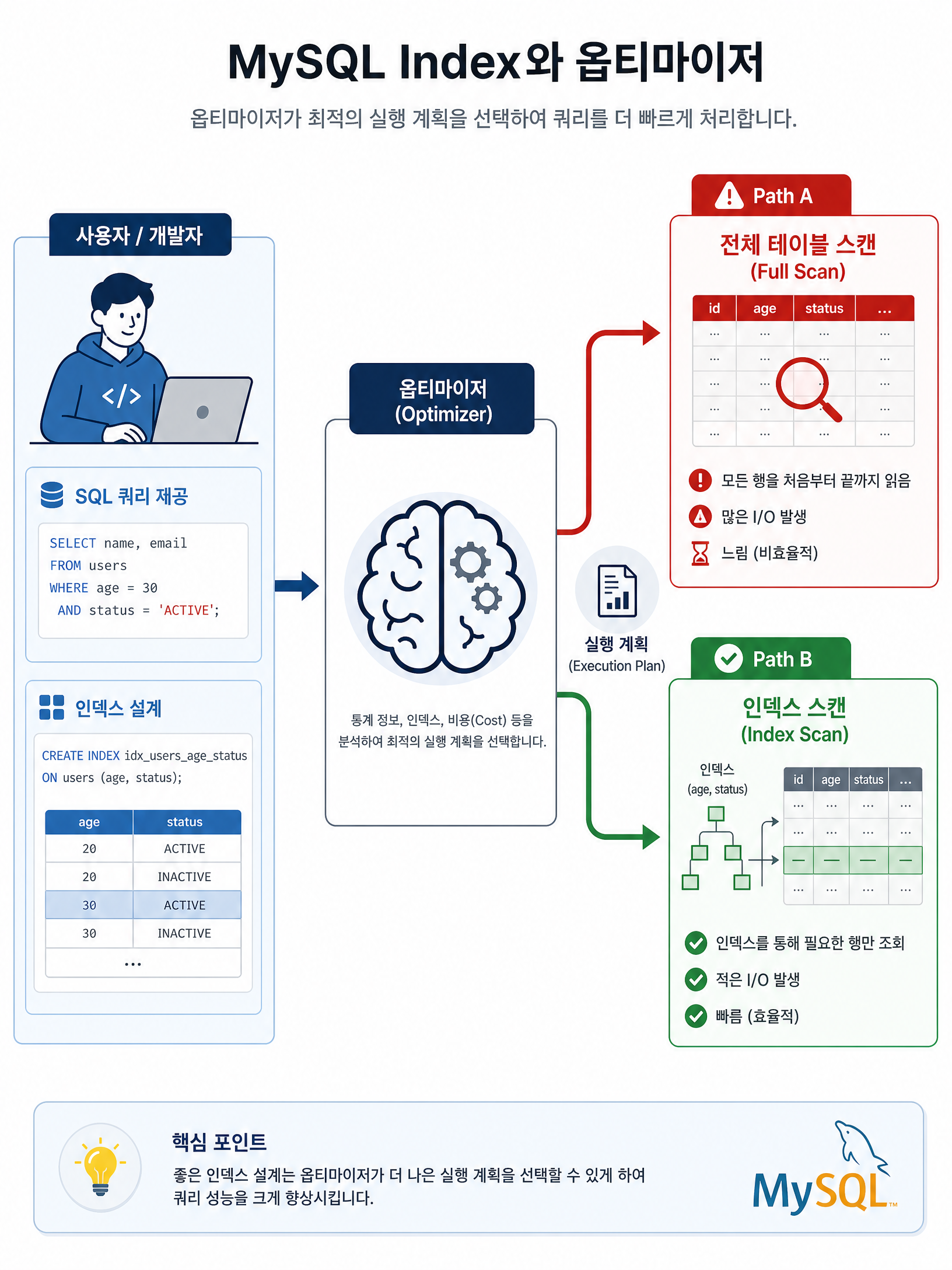
1. 인덱스는 직접 탐색 방식을 고르는 것이 아니다
많은 분이 오해하는 부분 중 하나가 “인덱스를 만들면 내가 원하는 방식으로 탐색하겠지?”라는 생각입니다. 하지만 인덱스를 만든다고 해서 개발자가 직접 Unique Scan이나 Range Scan 같은 탐색 방식을 지정할 수는 없습니다.
옵티마이저는 DB가 스스로 가장 효율적인 실행 방법을 고르는 두뇌입니다. 개발자는 인덱스를 잘 설계하여 옵티마이저에게 선택지를 제공하고, 실제 사용 여부는
EXPLAIN으로 확인해야 합니다.
실제로 인덱스를 사용할지, 아니면 그냥 테이블 전체를 읽는(Full Scan) 것이 빠를지는 전적으로 옵티마이저의 판단에 달려 있습니다. 데이터 양이 너무 적거나 인덱스를 타는 것보다 전체를 읽는 비용이 적다고 판단되면 옵티마이저는 우리가 정성껏 만든 인덱스를 무시하기도 합니다.
2. EXPLAIN으로 실행 계획 들여다보기
인덱스를 설계했다면, 이제 내 의도대로 동작하는지 확인해야 합니다. MySQL에서는 EXPLAIN 명령어로 이를 확인할 수 있습니다. 초보자가 우선적으로 살펴봐야 할 항목은 다음 세 가지입니다.
| 항목 | 의미 | 확인 기준 |
|---|---|---|
| type | 데이터를 어떻게 찾는지 (접근 방식) | ALL이면 주의, ref/range/const면 양호 |
| key | 실제 사용된 인덱스 | NULL이면 인덱스를 사용하지 않음 |
| rows | 읽을 것으로 예상되는 행 수 | 작을수록 좋음 |
특히 type 컬럼은 성능의 핵심 지표입니다. 아래는 자주 마주치는 주요 값들입니다.
- const: PK나 Unique Index로 단 한 건을 찾는 가장 효율적인 방식입니다.
- ref: 일반 인덱스를 사용하여 조건에 맞는 데이터를 찾는 방식입니다.
- range: 범위 조건(
>,<,BETWEEN등)을 사용하여 인덱스를 탐색합니다. - index: 인덱스 전체를 읽는 방식(
Full Index Scan)입니다. 테이블 전체보다는 낫지만 효율적이진 않습니다. - ALL: 테이블 전체를 읽는 방식(
Table Full Scan)입니다. 데이터가 많다면 성능 저하의 주범이 됩니다.
3. 헷갈리기 쉬운 개념 바로잡기
인덱스를 공부하다 보면 여러 용어가 섞여 혼란을 주기도 합니다. 명확히 짚고 넘어가야 할 두 가지가 있습니다.
Table Full Scan은 인덱스 탐색이 아니다
EXPLAIN의 type이 ALL로 나온다면 인덱스를 전혀 사용하지 않고 테이블을 처음부터 끝까지 읽었다는 뜻입니다. 이건 인덱스 탐색 방식 중 하나가 아니라, 인덱스 활용에 실패한 상태로 봐야 합니다.
Index Condition Pushdown (ICP)
Extra 컬럼에 Using index condition이라는 메시지가 보인다면 MySQL의 최적화 기능인 ICP가 작동하고 있다는 뜻입니다. 스토리지 엔진 단계에서 인덱스 조건을 먼저 걸러내 테이블 데이터에 접근하는 횟수를 크게 줄여줍니다. 초보자라면 “인덱스를 더 똑똑하게 활용하도록 돕는 보조 장치” 정도로 이해해도 충분합니다.
4. 복합 인덱스 설계의 핵심
하나의 컬럼만으로 부족할 때는 여러 컬럼을 묶은 복합 인덱스(Composite Index)를 사용합니다. 이때 가장 중요한 것은 컬럼의 순서입니다. 복합 인덱스는 왼쪽 컬럼부터 순서대로 정렬되어 관리되기 때문입니다.
예를 들어 아래와 같은 쿼리가 자주 실행된다고 가정해 봅시다.
1
2
3
4
5
SELECT *
FROM orders
WHERE member_id = 1
ORDER BY created_at DESC
LIMIT 20;
이 경우 단순히 member_id에만 인덱스를 거는 것보다, 아래와 같이 복합 인덱스를 구성하는 것이 훨씬 효율적입니다.
1
2
CREATE INDEX idx_orders_member_created_at
ON orders(member_id, created_at DESC);
이렇게 하면 member_id로 먼저 필터링한 뒤, 이미 정렬된 created_at 정보를 바로 사용하여 별도의 정렬 작업 없이 페이징 처리를 할 수 있습니다.
5. 인덱스, 많을수록 좋을까?
인덱스는 ‘공짜’가 아닙니다. 조회 성능을 얻는 대신 우리는 다음의 비용을 지불해야 합니다.
- 쓰기 성능 저하:
INSERT,UPDATE,DELETE발생 시 인덱스도 함께 갱신해야 하므로 속도가 느려집니다. - 저장 공간 증가: 인덱스 자체도 물리적인 저장 공간을 차지합니다.
- 관리 복잡도: 사용하지 않는 인덱스가 쌓이면 옵티마이저가 최적의 실행 계획을 세우는 데 방해가 될 수 있습니다.
따라서 인덱스는 자주 실행되는 쿼리 패턴에 맞게 꼭 필요한 만큼만 추가하는 절제가 필요합니다. 특히 status, gender처럼 값의 종류가 적고 선택도(Selectivity)가 낮은 컬럼은 단독 인덱스로는 큰 효과를 보기 어렵습니다. 이런 컬럼들은 다른 조건과 묶어 복합 인덱스로 활용하는 것이 좋습니다.
공부하면서 느낀 점
이전에 JPA와 QueryDSL을 정리하면서 느꼈던 점이지만, 추상화된 도구를 잘 쓰는 것만큼이나 그 밑바닥에 흐르는 데이터베이스의 원리를 이해하는 것이 정말 중요하다는 것을 다시 한번 체감했습니다. 인덱스는 단순히 성능을 높이는 마법의 도구가 아니라, 데이터의 흐름을 설계하는 정교한 기술이었습니다.
“어떤 인덱스가 필요할까?”라는 질문은 결국 “사용자가 우리 서비스를 어떻게 이용하는가?”라는 질문과 맞닿아 있습니다. 쿼리 패턴을 분석하고 실행 계획을 확인하는 습관을 들여, 비용 효율적인 시스템을 만드는 개발자가 되어야겠습니다.
한 줄 정리
인덱스는 많이 추가하는 기술이 아니라, 자주 실행되는 쿼리를 더 적은 비용으로 처리하기 위해 설계하는 기술이다.