Spring Cache: 캐시 Key 설계부터 동기화, RedisTemplate 동작 원리까지
들어가면서
Spring 애플리케이션에서 성능 최적화를 이야기할 때 캐시는 빠지지 않습니다. 데이터베이스 부하를 줄이고 응답 속도를 끌어올리는 데 특히 효과가 큽니다. 하지만 @Cacheable 어노테이션 하나 붙이는 것만으로는 부족합니다. 캐시 키를 어떻게 설계할지, 데이터가 바뀔 때 캐시를 어떻게 동기화할지, RedisTemplate이 내부적으로 어떻게 동작하는지까지 이해해야 안정적이고 효율적인 캐시 시스템을 만들 수 있습니다.
이 글에서는 실제 Spring Boot 프로젝트에서 캐시를 설계하며 마주쳤던 고민의 흐름을 따라 캐시 Key 설계, 캐시 동기화 책임, RedisTemplate의 동작 원리까지 다룹니다. 개념을 나열하기보다 왜 이렇게 설계하는 편이 유지보수성과 책임 분리에 유리한지를 실무 관점에서 풀어 보려고 합니다.
로컬 캐시와 원격 캐시
캐시는 크게 로컬 캐시와 원격 캐시로 나뉩니다. 두 방식의 특징을 알아야 캐시 전략을 제대로 세울 수 있습니다.
로컬 캐시: 애플리케이션 서버 내부에 데이터를 저장합니다. Caffeine이나
ConcurrentHashMap을 활용한 캐시가 대표적입니다. 같은 JVM 안에서 동작하니 객체 참조를 그대로 저장해도 문제가 없고 접근 속도도 매우 빠릅니다. 다만 서버 인스턴스마다 캐시를 따로 관리하기 때문에 인스턴스 사이의 데이터 일관성을 맞추기 어렵습니다.원격 캐시: 애플리케이션 서버와 별도의 저장소에 데이터를 둡니다. Redis가 대표적입니다. 여러 서버 인스턴스가 같은 캐시 데이터를 공유하므로 일관성 문제를 해결합니다. 대신 네트워크 통신을 거치는 만큼 로컬 캐시보다 접근 속도는 느립니다.
이 글에서는 원격 캐시인 Redis를 중심으로 캐시 설계와 동기화 전략을 다룹니다.
캐시 Key 네이밍 전략
캐시 Key는 캐시된 데이터를 식별하는 기준입니다. 의미를 분명히 전달하고 충돌을 막으려면 일관된 네이밍 전략이 필요합니다.
- 콜론(:)으로 계층 구조 표현:
user:1,product:category:electronics처럼 콜론으로 계층 구조를 드러내면 읽기 좋고 관리하기도 편합니다. - 고정 Prefix 사용:
user:,post:처럼 고정 Prefix를 붙여 Key의 역할을 구분합니다. Key 이름만 봐도 어떤 데이터의 캐시인지 바로 알 수 있습니다. - Key 이름만 보고 의미 이해 가능:
post:123:viewCount처럼 이름만으로 무엇이 캐시됐는지 파악되도록 설계합니다. - Key Prefix는 코드 상수로 관리: 매직 스트링을 피해 Key Prefix를 코드 상수로 두면 일관성이 유지되고 오타로 인한 오류도 줄어듭니다.
1
2
3
4
5
public class CacheKey {
public static final String USER_CACHE_PREFIX = "user:";
public static final String POST_CACHE_PREFIX = "post:";
public static final String PRODUCT_CACHE_PREFIX = "product:";
}
- 같은 캐시 그룹(value)을 유지하되, Key Prefix로 데이터 범위 구분: 가령
postCache라는 그룹 안에서 게시글 ID로 조회할 때와 사용자 이름으로 조회할 때를 나누려면postCache::id:1,postCache::username:kim처럼 Key Prefix를 활용하면 됩니다.
캐시 Key 충돌 방지
캐시 Key를 설계할 때 가장 조심해야 할 부분 중 하나가 Key 충돌입니다. 예를 들어 postId가 1이고 username이 "1"인 경우를 생각해 봅시다. 이때 postCache::1처럼 Key를 쓰면 postId가 1인 게시글 캐시와 username이 "1"인 사용자 캐시가 서로 충돌합니다.
이를 막으려면 Key에 Prefix를 덧붙여 데이터 타입을 분명히 구분해야 합니다.
1
2
3
4
5
6
7
// @Cacheable(value = "postCache", key = "#postId") // 충돌 가능성
@Cacheable(value = "postCache", key = "'id:' + #postId")
public Post getPostById(Long postId) { ... }
// @Cacheable(value = "postCache", key = "#username") // 충돌 가능성
@Cacheable(value = "postCache", key = "'username:' + #username")
public Post getPostByUsername(String username) { ... }
이렇게 id:, username: 같은 Prefix를 붙이면 실제 Redis에는 postCache::id:1, postCache::username:kim으로 저장돼 Key 충돌을 확실히 막을 수 있습니다.
TTL 설계 기준
TTL(Time To Live)은 캐시 데이터가 유효하게 유지되는 시간입니다. 어떻게 설정하느냐에 따라 캐시 효율과 데이터 최신성이 크게 달라집니다.
- 데이터 변경 주기가 길면 TTL을 길게: 자주 바뀌지 않는 데이터(예: 서비스 약관, 정적 설정 정보)는 TTL을 길게 잡아 캐시 히트율을 높입니다.
- 조회가 잦고 변경이 적은 데이터일수록 캐싱 효율이 높음: 이런 데이터일수록 캐시의 이점이 커지므로 TTL만 잘 잡아도 성능이 눈에 띄게 좋아집니다.
- TTL이 너무 짧으면 캐시 효율 감소: 캐시 데이터가 너무 빨리 만료되면 매번 DB를 다시 조회하게 되어 캐시를 둔 의미가 사라집니다.
- TTL이 너무 길면 데이터 최신성 저하: 캐시가 너무 오래 남아 있으면 실제 데이터와 어긋날 수 있습니다. 실시간성이 중요한 데이터라면 특히 문제가 됩니다.
데이터 특성과 서비스 요구사항을 함께 보고 TTL을 정하는 게 좋습니다. 필요하면 캐시 무효화 전략과 묶어서 조절합니다.
캐시 동기화 방법
데이터가 바뀌었을 때 캐시를 최신 상태로 맞추는 일을 캐시 동기화라고 합니다. Spring Cache에서는 주로 @CacheEvict와 @CachePut 어노테이션으로 처리합니다.
@CacheEvict: 메서드가 성공적으로 끝난 뒤 지정한 캐시를 삭제합니다. 다음 조회 때 DB에서 최신 데이터를 다시 읽어 캐싱합니다. 주로 데이터를 삭제하거나 변경할 때 기존 캐시를 무효화하려고 씁니다.1 2
@CacheEvict(value = "postCache", key = "'id:' + #postId") public void deletePost(Long postId) { ... }
@CachePut: 메서드가 성공적으로 끝난 뒤 반환 값을 지정한 캐시에 갱신합니다. 주로 데이터를 생성하거나 수정할 때 최신 데이터를 캐시에 반영하려고 씁니다.@Cacheable과 달리 메서드를 항상 실행합니다.1 2
@CachePut(value = "postCache", key = "'id:' + #result.id") public Post updatePost(Long postId, PostUpdateRequest request) { ... }
일반적인 수정·삭제 흐름에서는 @CacheEvict가 더 단순하고 안전합니다. @CachePut은 반환 값을 그대로 캐시에 저장하는 만큼 반환 값이 캐시할 데이터와 일치해야 합니다. @CacheEvict는 캐시를 지우기만 하므로 다음 조회 시점에 최신 데이터가 다시 캐시됩니다.
캐시 동기화 책임은 어디에 둘까?
캐시는 Redis, Caffeine, Spring Cache 같은 인프라 관심사입니다. 그래서 도메인 로직과 캐시 동기화 로직이 섞이면 좋지 않습니다. 순수 도메인 서비스가 RedisTemplate을 직접 알게 되면 비즈니스 규칙뿐 아니라 캐시 저장소의 구현 방식까지 떠안아 책임이 뒤섞입니다. 그러면 Redis 장애나 캐시 키 정책 변경, 캐시 전략 변경이 도메인 코드에까지 번지고 테스트도 복잡해집니다.
안 좋은 예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class ProductDomainService {
private final RedisTemplate<String, Object> redisTemplate;
public ProductDomainService(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public void decreaseStock(Product product, int quantity) {
product.decreaseStock(quantity);
// 도메인 서비스가 RedisTemplate을 직접 사용하여 캐시 삭제
redisTemplate.delete("product:" + product.getId());
}
}
위 예시에서 ProductDomainService는 재고 감소라는 도메인 규칙과 Redis 캐시 삭제라는 인프라 관심사를 한 클래스에 담고 있습니다. 그 결과 도메인 서비스의 순수성이 깨지고 캐시 기술을 바꿀 때 도메인 코드까지 손대야 합니다.
더 나은 구조:
캐시 동기화는 유스케이스 흐름을 조율하는 Application Service나 Facade에서 트리거하고 실제 Redis 조회·삭제·갱신은 CacheService나 CacheAdapter가 맡는 구조가 좋습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductRepository productRepository;
private final ProductCacheService productCacheService;
@Transactional
public void updateProduct(Long productId, ProductUpdateRequest request) {
Product product = productRepository.findById(productId)
.orElseThrow(() -> new IllegalArgumentException("Product not found"));
product.update(request.name(), request.price());
// Application Service에서 캐시 동기화 트리거
productCacheService.evictProduct(productId);
}
}
@Component
@RequiredArgsConstructor
public class ProductCacheService {
private final RedisTemplate<String, Object> redisTemplate;
public void evictProduct(Long productId) {
// CacheService가 실제 Redis 캐시 삭제 담당
redisTemplate.delete("product:" + productId);
}
}
이렇게 나누면 Application Service는 유스케이스 흐름을 맡고 ProductCacheService는 캐시 저장소와 캐시 키 정책을 맡습니다. 도메인 객체나 도메인 서비스는 Redis의 존재를 몰라도 되니 비즈니스 로직이 순수하게 유지됩니다. 계층마다 책임이 뚜렷해져 유지보수와 테스트도 쉬워집니다.
트랜잭션 커밋 이후 캐시 무효화
트랜잭션이 중요한 기능이라면 캐시를 언제 지우는지도 신경 써야 합니다. 트랜잭션 안에서 캐시를 먼저 지웠는데 데이터베이스 반영이 롤백되면, 실제 데이터는 그대로인데 캐시만 사라지는 데이터 불일치가 생깁니다. 결제나 주문, 재고처럼 정합성이 중요한 도메인에서는 이런 불일치 하나가 큰 사고로 이어집니다.
이럴 때는 트랜잭션이 커밋된 뒤에 캐시를 무효화하는 편이 안전합니다. Spring에서는 @TransactionalEventListener로 트랜잭션의 특정 단계(예: 커밋 이후)에 이벤트를 처리합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// ProductService 내에서 Product 업데이트 후 이벤트를 발행
@Service
@RequiredArgsConstructor
public class ProductService {
private final ApplicationEventPublisher eventPublisher;
// ...
@Transactional
public void updateProduct(Long productId, ProductUpdateRequest request) {
// ... product update logic ...
eventPublisher.publishEvent(new ProductUpdatedEvent(productId));
}
}
// ProductUpdatedEvent
public record ProductUpdatedEvent(Long productId) { }
// 캐시 서비스에서 이벤트를 리스닝하여 캐시 무효화
@Component
@RequiredArgsConstructor
public class ProductCacheService {
private final RedisTemplate<String, Object> redisTemplate;
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleProductUpdatedEvent(ProductUpdatedEvent event) {
redisTemplate.delete("product:" + event.productId());
}
}
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)를 붙이면 ProductUpdatedEvent는 트랜잭션이 성공적으로 커밋된 뒤에만 handleProductUpdatedEvent를 호출해 캐시를 무효화합니다. 트랜잭션 도중 롤백이 나면 이벤트 자체가 발행되지 않으니 캐시와 DB의 정합성이 그대로 유지됩니다.
RedisTemplate은 어떻게 Redis 명령을 실행할까?
RedisTemplate은 Spring이 제공하는 Redis용 클라이언트로, Java 코드로 Redis 명령어를 대신 실행해 주는 도구입니다. 메서드를 호출하면 내부적으로 Redis 명령어로 컴파일된다고 오해하는 경우가 많은데, 실제로는 그렇지 않습니다.
RedisTemplate의 메서드는 저마다 정해진 Redis 명령에 매핑돼 있습니다. 예를 들어 opsForValue().set()은 Redis의 SET 명령에, opsForValue().get()은 GET 명령에 대응됩니다.
이때 Redis는 Java 객체를 그대로 저장하지 못하기 때문에, Spring이 Serializer로 Key와 Value를 Redis가 알아들을 수 있는 byte[] 형태로 바꿉니다. 이 과정을 직렬화(Serialization)라고 합니다. 예전에 쓴 Redis 캐시에 객체를 저장할 때 직렬화가 필요한 이유 포스트에서 더 자세히 다뤘으니 함께 보면 좋습니다.
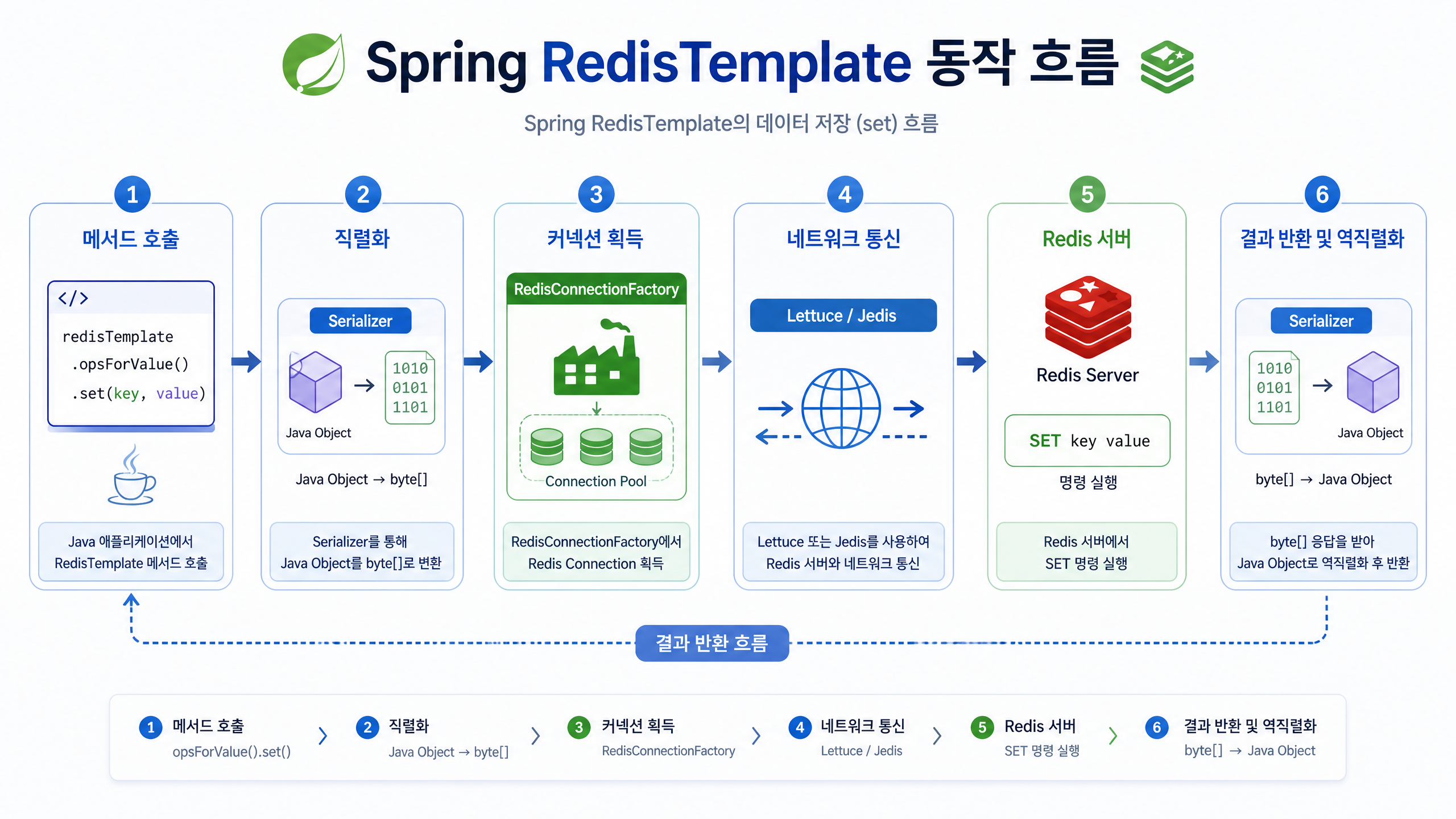
RedisTemplate은 다음 흐름으로 Redis 명령을 실행합니다.
- 메서드 호출:
RedisTemplate의opsForValue().set(key, value)같은 메서드를 호출합니다. - 직렬화: Key와 Value로 넘어온 Java 객체를 설정된
RedisSerializer(예:StringRedisSerializer,Jackson2JsonRedisSerializer)가 Redis가 이해할 수 있는byte[]형태로 직렬화합니다. - 커넥션 획득:
RedisTemplate이RedisConnectionFactory에서 Redis 서버와의 커넥션(RedisConnection)을 받아 옵니다. - 명령 실행: 얻어 온
RedisConnection으로 직렬화된 Key와 Value, 매핑된 Redis 명령(예:SET)을 Redis 서버에 보냅니다. 실제 네트워크 통신은 Lettuce나 Jedis 같은 Redis 클라이언트 라이브러리가 맡습니다. - 결과 역직렬화: Redis 서버에서 응답이 오면
RedisConnection이 이를 받아RedisSerializer로byte[]형태의 응답을 다시 Java 객체로 역직렬화합니다. - 커넥션 반환: 명령이 끝나면 커넥션은 정리되거나 커넥션 풀로 돌아가 재사용됩니다.
즉, RedisTemplate은 개발자가 Java 객체를 다루듯 Redis를 쓰도록 내부적으로 메서드 호출을 Redis 명령으로 매핑하고 데이터를 직렬화·역직렬화하며 커넥션을 관리해 Redis 서버와 통신하는 역할을 합니다.
공부/구현하면서 느낀 점
Spring Cache를 써 보며 가장 크게 느낀 점은 캐시를 단순한 성능 최적화 도구가 아닌, 하나의 독립적인 인프라 계층으로 바라보는 시각입니다. 처음에는 @Cacheable 어노테이션만으로 다 될 줄 알았는데, 막상 캐시 Key 설계와 동기화 전략, 트랜잭션 연계까지 챙길 부분이 많았습니다.
그중에서도 도메인 로직과 캐시 로직을 나누는 일이 유지보수에 특히 중요하다고 느꼈습니다. 도메인 서비스가 캐시의 존재를 모르게 해 두면 비즈니스 로직이 순수하게 유지됩니다. 덕분에 캐시 기술이나 정책이 바뀌어도 도메인 코드가 받는 영향을 줄일 수 있었습니다. 정합성이 중요한 상황에서는 트랜잭션 커밋 이후 캐시를 무효화해 데이터 불일치를 막는 일이 꼭 필요하다는 것도 알게 됐습니다.
RedisTemplate의 동작 원리를 알아 두니 캐시 문제를 디버깅하고 최적화할 때 도움이 많이 됐습니다. Java 객체가 Redis에 어떻게 저장되고 조회되는지 알고 나서는 직렬화 예외나 예상치 못한 캐시 동작을 훨씬 수월하게 이해하게 됐습니다. 이렇게 원리까지 파악해 두면 기능을 그냥 쓰는 데서 그치지 않고 시스템 전체의 안정성과 성능을 고려한 설계로 이어집니다.
한 줄 정리
Spring Cache는 어노테이션 몇 개로 끝나는 도구가 아니라, 캐시 Key 설계와 책임 분리, 트랜잭션 연계, 내부 동작 원리까지 이해해야 안정적이고 효율적으로 다룰 수 있는 인프라 계층이다.