AOP 기반 로깅 전략 — 이력 파이프라인으로 확장 가능한 시스템 설계
들어가면서
이전에 AOP를 정리하면서 “공통 로직은 어디에 있어야 할까?”에 대해 고민했었다. 실무에서 이 질문에 대한 가장 첫 번째 대답이자, AOP를 가장 먼저 적용하게 되는 곳이 바로 ‘로깅(Logging)’이라고 한다.
처음에는 단순히 에러가 났을 때 콘솔 창을 확인하기 위해 log.info()나 System.out.println()을 쓰는 정도로만 생각했다. 그런데 이런 조언을 들었다.
“나중에 로깅 시스템으로 이력 파이프라인을 만드는 것으로 확장도 가능하니, 로깅으로 남기는 방법을 제대로 알아보세요.”
단순히 에러 확인용이 아니라, 이력 파이프라인이라니. 그래서 로깅을 시스템 아키텍처 관점에서 어떻게 설계하고 확장할 수 있는지 알아보았다.
기존 방식의 한계: 코드에 흩어진 로그
가장 원시적인 로깅 방식은 비즈니스 로직 중간중간에 로그를 직접 작성하는 것이다.
1
2
3
4
5
6
7
8
@Service
public class OrderService {
public void createOrder(OrderRequest request) {
log.info("주문 생성 요청: {}", request);
// 비즈니스 로직
log.info("주문 생성 완료");
}
}
이 방식에는 치명적인 단점이 있다고 한다.
- 단일 책임 원칙(SRP) 위배: 비즈니스 로직과 로깅 로직이 섞여 있다.
- 유지보수 어려움: 로깅 포맷을 바꾸거나 로깅 대상을 추가하려면 모든 코드를 수정해야 한다.
이 문제를 해결하기 위해 AOP(Aspect-Oriented Programming)를 활용할 수 있다.
AOP를 활용한 로깅 자동화
AOP를 사용하면 비즈니스 로직을 건드리지 않고도 원하는 시점에 로그를 남길 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Aspect
@Component
@Slf4j
public class LoggingAspect {
@Around("execution(* com.example.api..*Controller.*(..))")
public Object logRequestAndResponse(ProceedingJoinPoint joinPoint) throws Throwable {
String methodName = joinPoint.getSignature().getName();
Object[] args = joinPoint.getArgs();
log.info("[REQUEST] {} - args: {}", methodName, Arrays.toString(args));
Object result = joinPoint.proceed();
log.info("[RESPONSE] {} - result: {}", methodName, result);
return result;
}
}
이렇게 하면 Controller로 들어오는 모든 요청과 응답을 일관된 포맷으로 남길 수 있다. 하지만 실무에서는 여기서 한 발 더 나아간다고 한다.
MDC(Mapped Diagnostic Context)를 활용한 추적
여러 사용자가 동시에 요청을 보내는 웹 환경에서는 콘솔에 찍힌 로그들이 뒤섞이게 된다. 어떤 로그가 어떤 사용자의 요청인지 구분하려고 MDC를 활용한다고 한다.
참고로 MDC는 Filter에서 구현하는데, Filter의 역할과 동작 방식을 이전에 정리한 적이 있다.
MDC는 스레드 로컬(ThreadLocal)에 데이터를 저장하여 동일한 스레드에서 로그를 남길 때 특정 정보를 함께 출력하도록 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Component
public class TraceIdFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) {
String traceId = UUID.randomUUID().toString().substring(0, 8);
MDC.put("traceId", traceId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.clear();
}
}
}
Logback 설정(logback-spring.xml)에서 %X{traceId}를 추가하면 이런 식으로 출력된다:
1
2
3
[2026-05-11 10:00:00] [INFO] [traceId: a1b2c3d4] [OrderController] - [REQUEST] createOrder
[2026-05-11 10:00:01] [INFO] [traceId: a1b2c3d4] [OrderService] - 비즈니스 로직 처리 중...
[2026-05-11 10:00:02] [INFO] [traceId: a1b2c3d4] [OrderController] - [RESPONSE] createOrder
요청의 시작부터 끝까지 하나의 traceId로 묶어서 흐름을 추적할 수 있는 구조다.
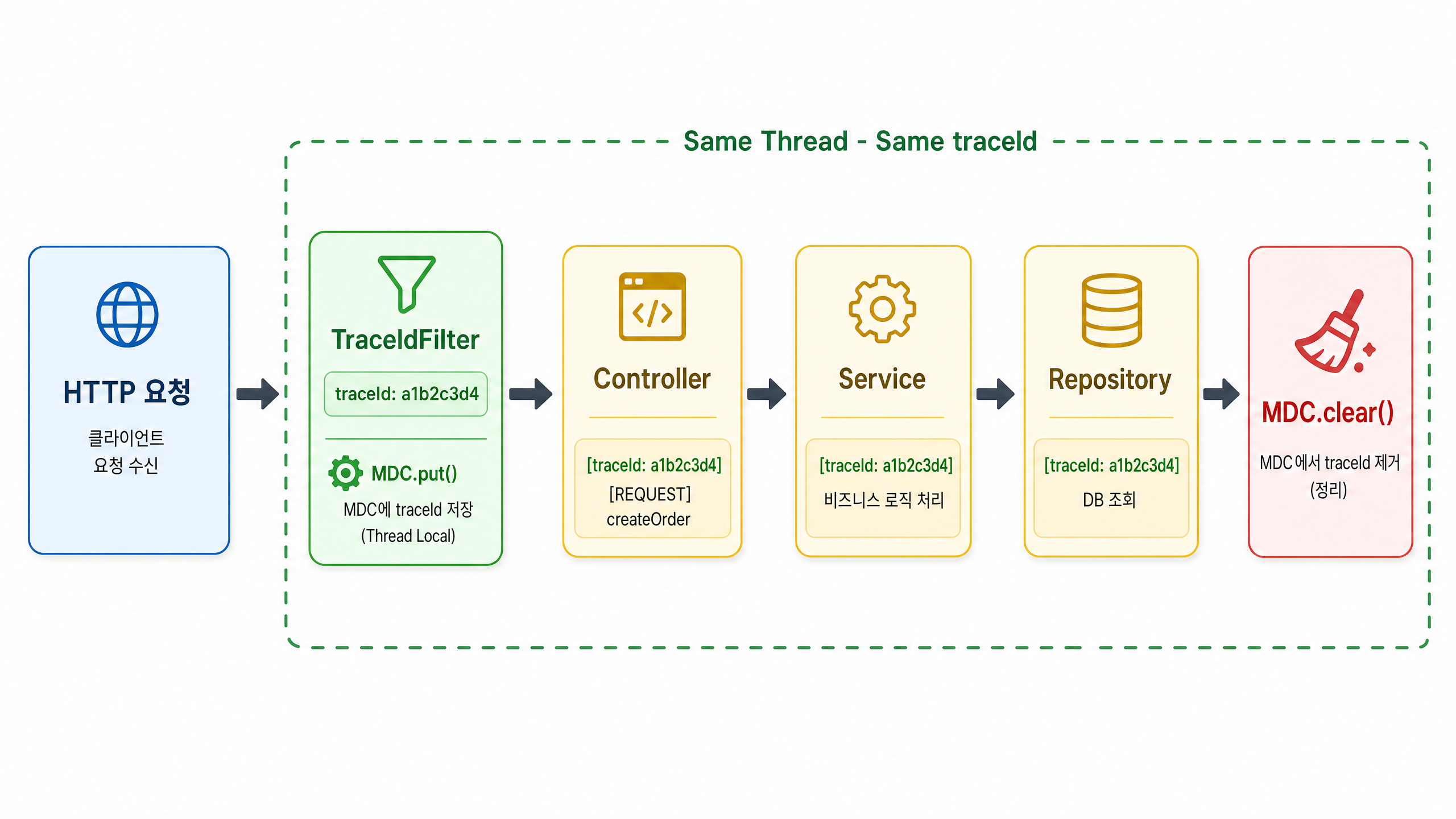
확장: 단순 로그에서 이력 파이프라인으로
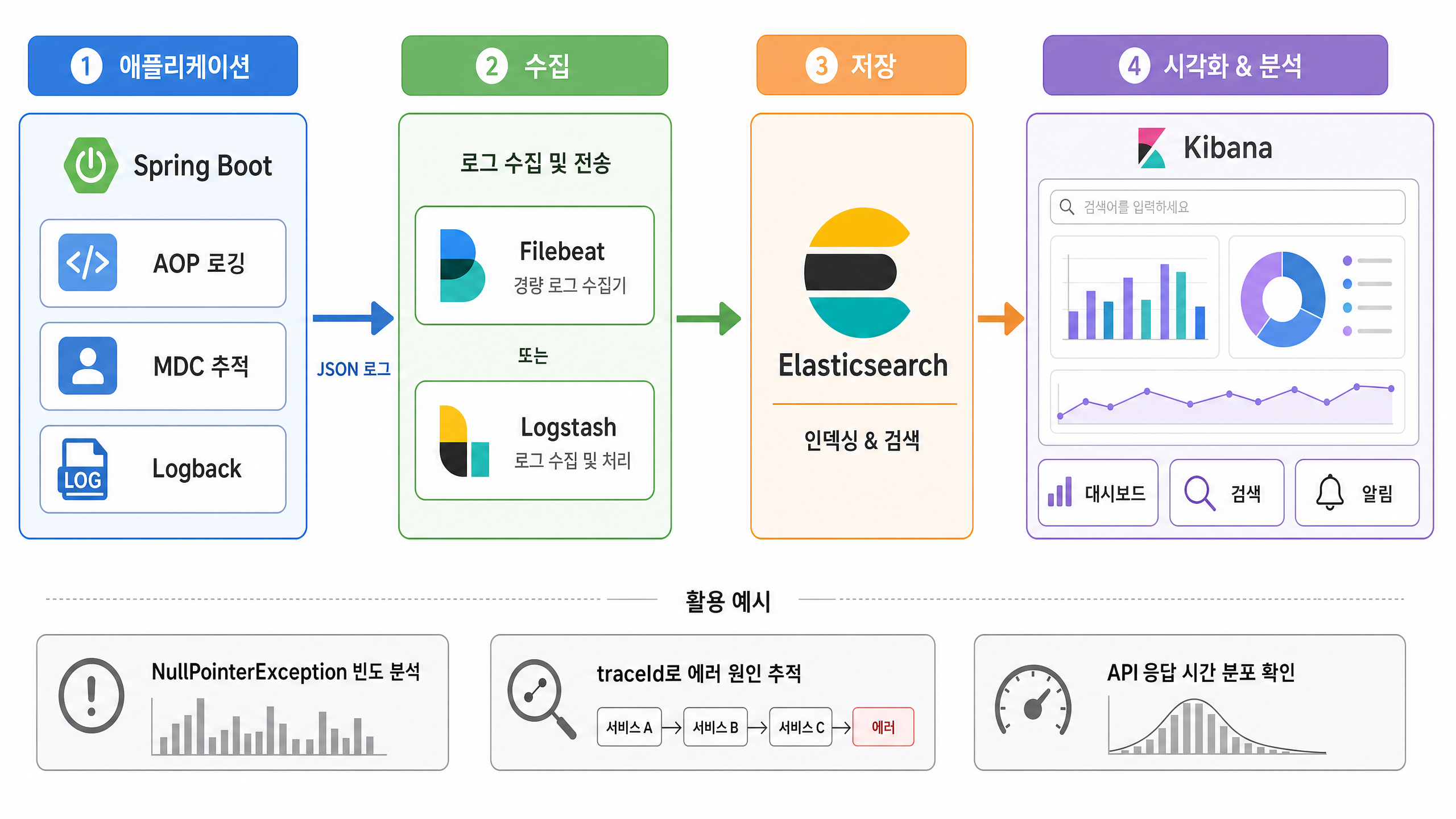
여기까지가 애플리케이션 레벨의 로깅이라면, 이것을 데이터 파이프라인으로 확장하는 그림도 있다.
단순히 콘솔에 찍고 버리는 로그가 아니라, 이력을 영구적으로 보관하고 분석할 수 있는 시스템을 구축하는 것이다. 대표적으로 ELK Stack (Elasticsearch, Logstash, Kibana)이 있다.
1. Logback Appender 설정으로 파일 분리
먼저 에러 로그, 비즈니스 로그, 시스템 로그를 용도별로 파일로 분리하여 적재한다.
1
2
3
4
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/myapp/application.log</file>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
특히 LogstashEncoder를 사용하면 로그를 JSON 형태로 남길 수 있어, 이후 파이프라인에서 파싱하기가 훨씬 수월해진다.
2. Logstash 또는 Filebeat를 통한 수집
서버에 적재된 로그 파일을 Filebeat나 Logstash가 읽어들여 중앙 저장소로 전송한다.
3. Elasticsearch에 적재 및 Kibana 시각화
수집된 로그 데이터는 Elasticsearch에 인덱싱되고, Kibana 대시보드를 통해 시각화된다.
이 파이프라인이 구축되면 이런 일들이 가능해진다고 한다.
- “최근 1시간 동안 발생한 NullPointerException 빈도수 확인”
- “특정 사용자의 traceId를 검색하여 에러 발생 원인 추적”
- “결제 실패 API의 응답 시간 분포 분석”
공부하면서 느낀 점
처음에는 단순히:
“에러가 났을 때 원인을 빨리 찾으려고 로그를 남기는 거 아닌가?” 정도로만 이해하고 있었다.
그런데 AOP 기반 자동화, MDC를 이용한 추적, ELK 파이프라인까지 흐름을 따라가 보니 로깅의 본질이 다르게 보이기 시작했다. 잘 설계된 로그는 단순한 디버깅 도구가 아니라, 시스템의 비즈니스 이력이자 귀중한 데이터 자산이 될 수 있다는 것이다.
아직 직접 파이프라인을 구축해 본 것은 아니지만, 이 흐름을 알고 나니 코드에 log.info() 한 줄을 적을 때도 “이 로그가 나중에 어떻게 쓰일 수 있을까?”를 한 번 더 생각하게 될 것 같다.
한 줄 정리
로깅은 단순한 디버깅 도구가 아니라, 시스템의 이력을 설계하고 추적하는 데이터 파이프라인의 시작점이다.
References
- Spring Framework Documentation - Aspect Oriented Programming with Spring
- SLF4J Manual
- Logback Project - Mapped Diagnostic Context
- Elastic Stack - Getting Started
- 이전 포스트 - Filter vs Interceptor vs AOP — 어디서 무엇을 처리해야 할까
- 이전 포스트 - Filter를 이해하면서 정리한 생각 — 인증은 어디서 시작되는가
- 이전 포스트 - AOP를 이해하면서 정리한 생각 — 공통 로직은 어디에 있어야 할까