JPA와 QueryDSL: Q타입, Repository 역할, 동적 쿼리, 연관관계 설계까지 정리하기
들어가면서
JPA로 엔티티와 리포지토리를 다루는 데 익숙해질 무렵, 문득 이런 고민이 들었습니다. “단순한 CRUD는 JpaRepository로 충분한데, 검색 조건이 복잡해지면 어떻게 해야 할까?” 처음에는 메서드 이름 쿼리나 JPQL을 활용했지만, 검색 조건이 늘어나고 동적으로 변해야 할 때마다 코드가 지저분해지고 유지보수가 어려워지곤 했습니다. 특히 문자열 기반의 JPQL은 컴파일 시점에 오류를 잡기 어렵고, 리팩토링할 때도 신경 쓸 부분이 많아 불편함이 컸습니다. 그러다 QueryDSL이라는 기술을 알게 됐고, 이번 글에서는 QueryDSL을 처음 학습하면서 헷갈렸던 개념들을 정리해보려 합니다. JPA에 익숙하지만 QueryDSL이 낯선 백엔드 개발자분들께 도움이 되기를 바랍니다.
1. 기존 JPA만 사용할 때의 불편함
JPA는 객체지향적으로 데이터를 관리하게 해주어 개발 생산성을 크게 높여줍니다. 특히 Spring Data JPA의 JpaRepository는 기본적인 CRUD(Create, Read, Update, Delete) 작업을 매우 간편하게 처리하도록 돕습니다. findById(), save(), delete()와 같은 메서드만으로도 대부분의 간단한 데이터 조작이 가능하죠.
하지만 현실이 늘 단순하지만은 않습니다. 특정 조건에 맞는 데이터를 검색해야 하거나, 여러 테이블을 조인해 복잡한 데이터를 조회해야 하는 상황이 자주 생깁니다. 이때 JpaRepository의 메서드 이름 쿼리(findByUsernameAndAgeGreaterThan())는 이름이 너무 길어지거나 표현할 수 있는 조건에 한계가 있습니다. JPQL(Java Persistence Query Language)을 쓰면 좀 더 유연하게 쿼리를 작성할 수 있지만, 이것도 결국 문자열 기반의 쿼리입니다.
문자열 기반 JPQL의 가장 큰 단점은 컴파일 시점에 오류를 잡기 어렵다는 점입니다. 오타나 잘못된 문법이 있어도 애플리케이션을 실행하기 전까지는 알 수 없죠. 엔티티의 필드 이름이 바뀌거나 구조가 달라졌을 때 JPQL 문자열을 일일이 찾아 고쳐야 해서 리팩토링에도 취약합니다.
이런 불편함 속에서 QueryDSL은 빛과 소금 같은 존재로 다가옵니다. 자바 코드로 쿼리를 작성하게 해주어 컴파일 시점에 오류를 잡고 타입 안전성을 보장하죠. 이제 QueryDSL의 핵심 개념들을 하나씩 살펴보겠습니다.
2. QueryDSL의 Q타입 개념
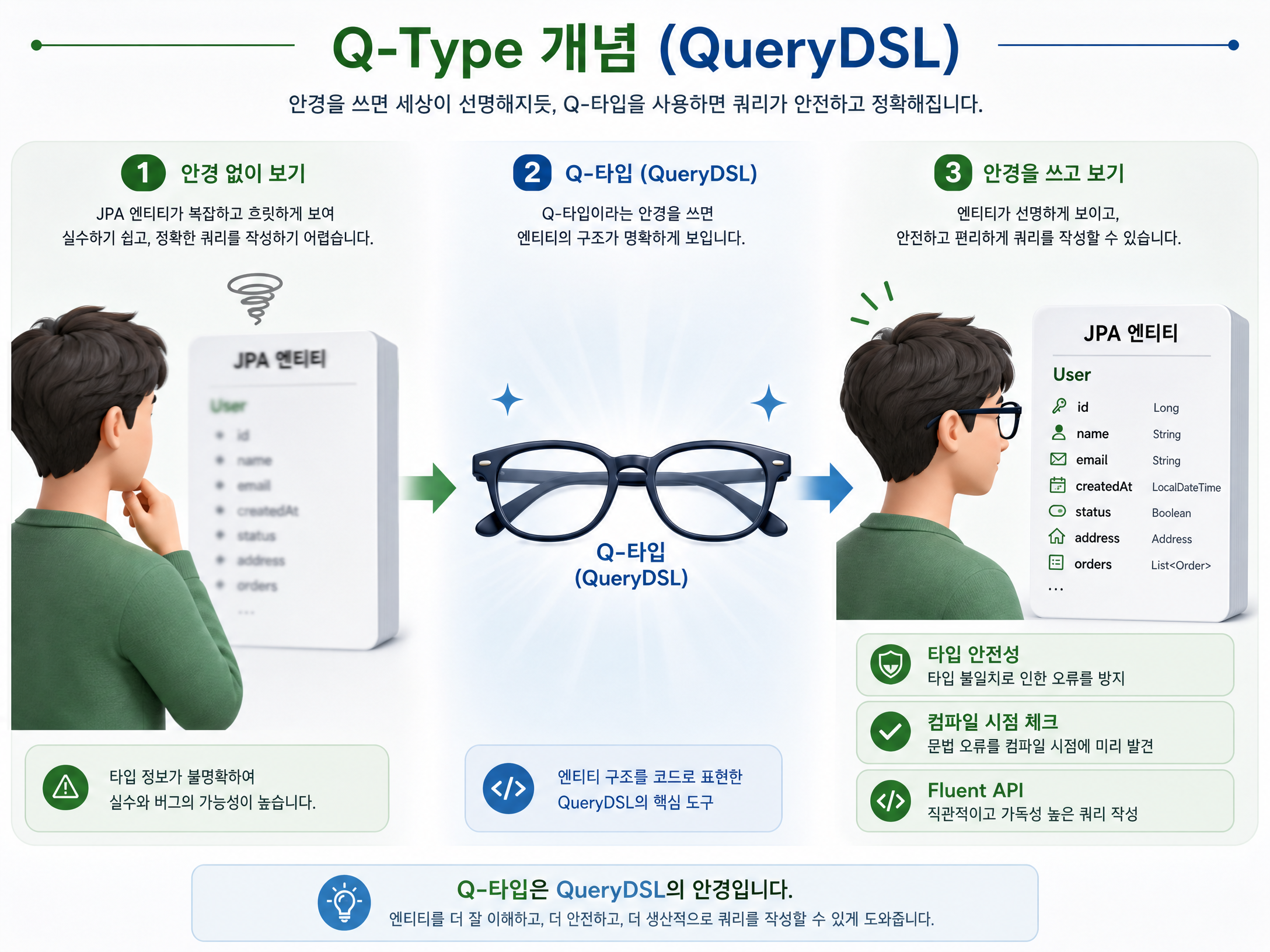
QueryDSL을 처음 접하면 가장 먼저 만나는 개념 중 하나가 바로 Q타입(Q-Type)입니다. QueryDSL은 빌드 시점에 Q타입 클래스를 자동으로 생성하는데, 이 때문에 많은 개발자가 Q타입을 마치 “엔티티를 대신 만들어주는 것”으로 오해하곤 합니다. 하지만 정확한 이해는 아닙니다.
정확히 말하면 Q타입은 “이미 존재하는 엔티티를 보고, 검색용 클래스를 추가로 만들어주는 것”입니다. 엔티티는 실제 데이터베이스 테이블과 매핑되는 비즈니스 객체이고, Q타입은 이 엔티티를 바탕으로 쿼리를 작성하는 메타데이터 역할을 합니다.
이해를 돕기 위해 비유를 들어 설명해볼까요?
- 엔티티: 도서관에 실제로 꽂혀 있는 책 한 권 한 권입니다. 이 책들이 실제 정보(데이터)를 담고 있죠.
- Q타입: 그 책을 찾기 쉽게 만든 검색 색인입니다. 책의 제목, 저자, 출판일 등 검색에 필요한 정보를 미리 정리해둔 것이죠. 이 색인 자체는 책의 내용을 담고 있지 않습니다.
- QueryDSL: 이 검색 색인(Q타입)으로 원하는 책(엔티티)을 효율적으로 찾는 검색 도구입니다.
이 비유에서 보듯, 검색 색인이 자동으로 만들어져도 실제 책이 먼저 도서관에 꽂혀 있어야 하듯이 Q타입도 엔티티가 먼저 정의돼 있어야 생성됩니다. Q타입은 엔티티의 필드와 메서드를 바탕으로 쿼리 표현식을 만들고, 덕분에 타입 안전한 쿼리를 작성할 수 있습니다.
3. POJO와 헷갈릴 수 있는 이유
QueryDSL의 Q타입은 때때로 POJO(Plain Old Java Object)처럼 오해받기도 합니다. 그 이유는 다음과 같습니다.
- 자동 생성된다: 개발자가 직접 작성하지 않고 빌드 시점에 자동으로 생성되니, 마치 프레임워크가 제공하는 일반적인 객체처럼 느껴질 수 있습니다.
- 자바 객체처럼 필드에 접근한다:
qBook.title,qBook.author처럼 마치 엔티티 객체의 필드에 접근하듯 사용할 수 있습니다. - 문자열 쿼리가 아니라 객체 기반으로 쓴다: JPQL처럼 문자열로 쿼리를 작성하는 게 아니라 자바 객체와 메서드 호출로 쿼리를 구성하므로, 일반적인 자바 코드와 비슷하게 느껴집니다.
하지만 Q타입은 비즈니스 로직을 담는 POJO와는 명확히 다릅니다.
POJO는 특정 프레임워크나 기술에 강하게 의존하지 않는 순수 자바 객체를 말합니다. 비즈니스 로직과 데이터를 담고 있으며, 재사용성과 테스트 용이성이 높다는 장점이 있습니다.
반면 Q타입은 QueryDSL이 쿼리 작성을 위해 생성하는 보조 클래스이자 메타 정보 클래스입니다. 엔티티의 구조를 반영해 쿼리 표현식을 만드는 데 특화돼 있고, 비즈니스 로직은 포함하지 않습니다. Q타입은 쿼리 빌더 역할을 하는 QueryDSL 라이브러리에 강하게 의존하는 객체이므로 POJO의 정의와는 거리가 있습니다.
이 차이를 알아야 QueryDSL을 제대로 활용할 수 있습니다.
4. QueryDSL을 쓰면 기존 JpaRepository는 필요 없는가?
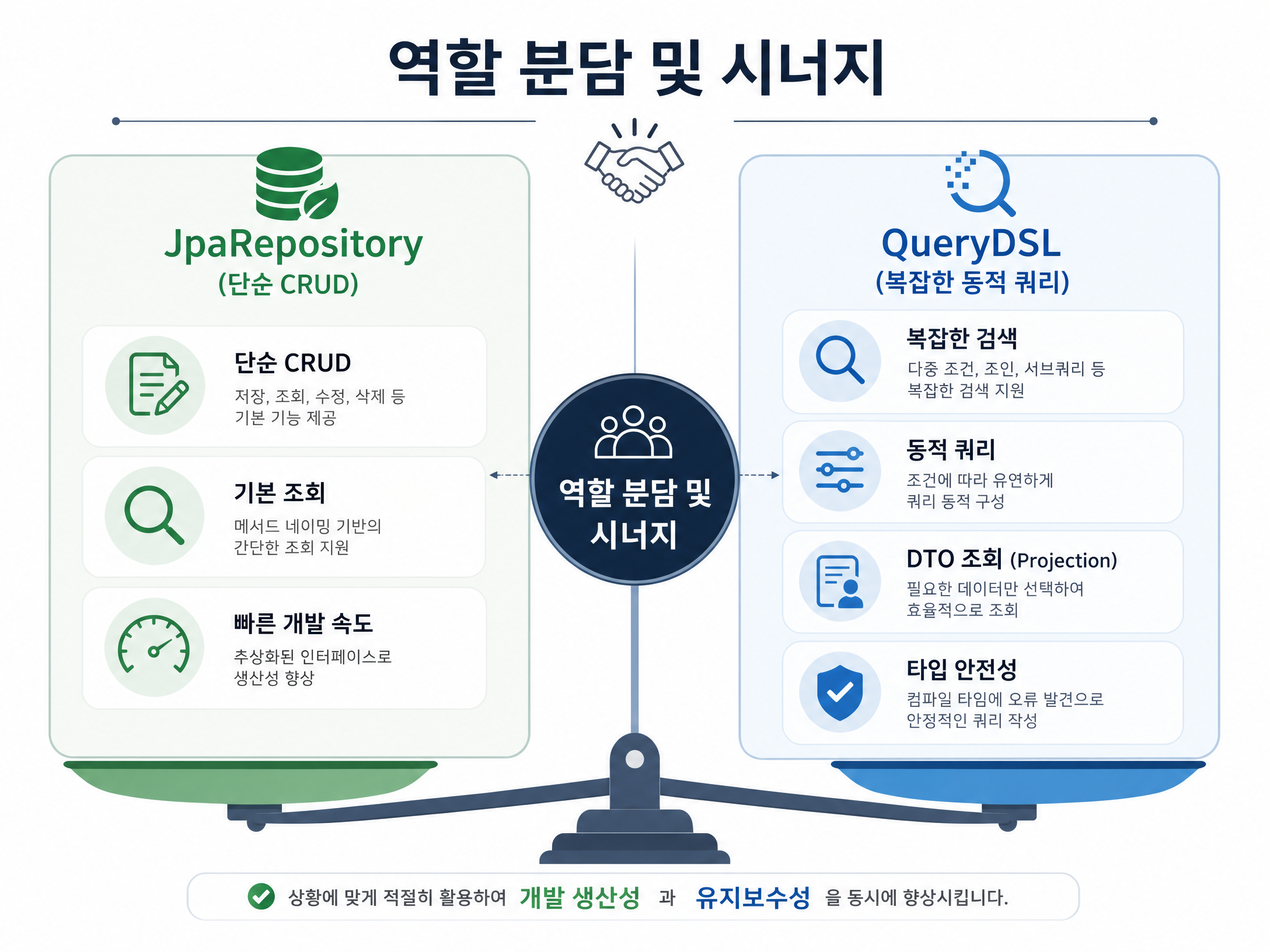
QueryDSL을 쓰기 시작하면 “그럼 이제 JpaRepository는 필요 없는 건가?”라는 의문이 들 수 있습니다. 결론부터 말하면, 필요 없어진 게 아니라 역할이 나뉘는 것입니다.
JpaRepository와 QueryDSL은 서로를 대체하는 관계가 아니라, 각자의 강점을 살려 시너지를 내는 보완적인 관계입니다.
JpaRepository의 역할:
- 기본 CRUD:
save(),findById(),delete()등 기본적인 데이터 생성, 조회, 수정, 삭제 기능을 제공합니다. - 간단한 메서드 쿼리:
findByUsername(),findByEmailAndStatus()처럼 간단한 조건의 조회는 메서드 이름만으로도 충분히 처리합니다.
QueryDSL Custom Repository의 역할:
- 복잡한 검색 조건: 여러 필드를 조합하거나 동적으로 조건을 추가해야 하는 복잡한 검색 쿼리에 강점이 있습니다.
- 동적 쿼리: 런타임에 따라 검색 조건이 달라지는 유연한 쿼리를 작성할 수 있습니다.
- 정렬, 필터, 조인 조건이 많은 조회: 여러 엔티티를 조인하고 다양한 정렬 및 필터링 조건을 적용해야 하는 복잡한 조회 쿼리를 타입 안전하게 작성할 수 있습니다.
QueryDSL은
JpaRepository가 제공하는 기본 기능을 완전히 대체하는 게 아니라,JpaRepository만으로는 처리하기 어려운 복잡한 조회 기능을 보완하는 도구입니다. 보통JpaRepository가 기본적인 데이터 접근을 맡고, QueryDSL이Custom Repository로 복잡하고 동적인 조회 쿼리를 맡는 식으로 역할을 나눕니다. 그러면 코드의 가독성과 유지보수성도 좋아집니다.
5. 단일 책임 원칙과 동적 검색 조건
동적 검색 조건을 처리하는 Repository를 설계할 때 “검색 조건이 여러 개인데, 이게 단일 책임 원칙(Single Responsibility Principle, SRP)을 위반하는 건 아닐까?”라는 고민이 들 수 있습니다. 하지만 검색 Repository가 여러 조건을 처리하더라도 SRP를 위반한다고 보기는 어렵습니다.
단일 책임 원칙은 “하나의 클래스 또는 함수가 한 가지 이유로만 변경되어야 한다”는 의미입니다. 변경의 이유가 하나여야 한다는 것이 핵심입니다.
검색 Repository의 주된 책임은 “데이터를 검색하는 것”입니다. 이 “검색”이라는 책임 안에서 다양한 입력 조건(예: 사용자 이름, 나이, 상태 등)을 처리하는 것은 자연스러운 일입니다. 검색 조건이 추가되거나 바뀔 때마다 Repository 자체가 바뀌는 게 아니라 검색 로직 내부의 조건 구성 방식이 바뀌는 것이므로, SRP를 위반한다고 보기 어렵습니다.
예를 들어 UserRepository가 사용자 정보를 저장하고 조회하는 책임을 가진다고 할 때, findUsersByConditions(SearchCondition condition) 같은 메서드가 여러 검색 조건을 처리하더라도 이 메서드의 변경 이유는 여전히 “사용자 검색 로직의 변경”에 해당합니다. 따라서 단일 책임 원칙을 잘 지키고 있다고 볼 수 있습니다.
6. BooleanBuilder와 BooleanExpression 비교
QueryDSL로 동적 쿼리를 작성할 때 BooleanBuilder와 BooleanExpression은 자주 쓰이는 두 가지 방식입니다. 이 둘의 차이를 분명히 알아둘 필요가 있습니다.
| 구분 | BooleanBuilder | BooleanExpression |
|---|---|---|
| 개념 | 조건을 모아두는 컨테이너 | 단일 조건의 표현식 |
| 객체 성격 | 가변(Mutable) | 불변(Immutable) |
| null 처리 | 직접 제어 (조건 추가 전 null 체크 필요) | where절에서 null 자동 무시 |
| where 작성 방식 | .where(builder) | .where(조건1, 조건2, 조건3) |
| 재사용성 | 낮음 (상태를 가지므로) | 높음 (함수형 조합 가능) |
| 코드 가독성 | 복잡해질 수 있음 (조건이 많아질수록) | 비교적 깔끔함 (조건별 메서드 분리 가능) |
언제 어떤 방식을 쓰면 좋을까?
BooleanBuilder: 조건을 반복문이나 분기문으로 유연하게 추가·삭제해야 하는 경우에 유용합니다. 예를 들어 여러 검색 필드 중 사용자가 입력한 값에 따라 동적으로 조건을 구성해야 할 때 적합합니다. 다만 가변 객체이므로 상태 관리에 주의해야 하고, 조건이 많아질수록 코드가 복잡해질 수 있습니다.BooleanExpression: 조건 메서드를 분리하고null만 무시하면 되는 경우에 더 적합합니다.where절에 여러BooleanExpression을 콤마(,)로 구분해 전달하면null인 조건은 자동으로 무시됩니다. 불변 객체라 재사용성이 높고, 각 조건을 별도 메서드로 분리해 코드 가독성을 높일 수 있습니다.
실무에서는
BooleanExpression방식이 재사용성과 가독성 측면에서 더 선호되는 경우가 많습니다. 각 검색 조건을 작은 단위의BooleanExpression메서드로 분리해 조합하면, 코드를 더 깔끔하고 유지보수하기 쉽게 만들 수 있습니다.
7. Projections.constructor()
QueryDSL로 데이터를 조회할 때 엔티티 객체 대신 특정 필드만 담는 DTO(Data Transfer Object)로 바로 조회하고 싶을 때가 있습니다. 이때 Projections.constructor()를 활용할 수 있습니다.
Projections.constructor()는 DTO의 생성자를 이용해 결과를 매핑하는 방식입니다. DTO에 @QueryProjection 어노테이션을 쓰지 않고도 DTO로 직접 조회할 수 있다는 장점이 있죠. 다만 중요한 주의사항이 하나 있습니다.
Projections.constructor()는 DTO 생성자의 파라미터 순서와 타입이 QueryDSL 조회 결과의 순서 및 타입과 정확히 일치해야 합니다. DTO의 생성자 파라미터 순서나 타입이 바뀌면 런타임 오류가 날 수 있어, 변경에 취약하다는 단점이 있습니다.
예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// DTO
public class MemberDto {
private String username;
private int age;
public MemberDto(String username, int age) {
this.username = username;
this.age = age;
}
// Getter 생략
}
// QueryDSL 사용
List<MemberDto> result = queryFactory
.select(Projections.constructor(MemberDto.class, qMember.username, qMember.age))
.from(qMember)
.fetch();
대안:
Projections.constructor() 외에도 다음과 같은 대안들이 있습니다. 각 방식은 장단점이 있으니 상황에 맞게 고르면 됩니다.
Projections.fields(): DTO의 필드명과 QueryDSL 조회 결과의 별칭(alias)이 일치하면 값을 매핑합니다. 생성자 순서에 덜 민감하지만 필드명이 일치해야 합니다.Projections.bean():Projections.fields()와 비슷하게 동작하지만 Setter로 값을 주입합니다. 기본 생성자가 필요합니다.@QueryProjection: DTO 생성자에@QueryProjection어노테이션을 붙이면 QueryDSL 컴파일러가 해당 DTO를 위한 Q타입을 생성해줍니다. 컴파일 시점에 타입 체크가 가능해 가장 타입 안전한 방식이지만, DTO에 QueryDSL 의존성이 생긴다는 부담이 있습니다.
Projections.constructor()는 간단하게 DTO로 조회할 수 있는 방법이지만, 생성자 파라미터 순서에 의존하기 때문에 변경에 취약할 수 있다는 점은 늘 염두에 둬야 합니다.
8. “연관이 필요 없는 것은 JPA가, 조인이 필요한 것은 QueryDSL이 한다”는 의미
이 문장은 때때로 “JPA는 조인을 못하고 QueryDSL만 조인을 할 수 있다”는 오해를 부를 수 있습니다. 하지만 절대적인 규칙처럼 받아들이기보다는, 각 기술의 강점을 살려 효율적으로 개발하자는 의미로 이해하는 게 좋습니다.
정확히는 다음과 같은 의미로 해석할 수 있습니다.
- 단순 CRUD나 단순 조회는
JpaRepository로 충분합니다. 예를 들어 특정id로 엔티티를 조회하거나 간단한 조건으로 목록을 조회하는 것은JpaRepository의 기본 기능만으로도 충분하고 간편합니다. - 복잡한 조인, 검색 조건, DTO 조회는 QueryDSL이 더 적합합니다. 여러 엔티티를 복잡하게 조인해야 하거나 다양한 검색 조건을 동적으로 조합해야 할 때, QueryDSL은 자바 코드로 쿼리를 작성하게 해주어 타입 안전성을 보장하고 가독성을 높여줍니다.
- JPA도 조인이 가능하지만, 복잡한 조회 쿼리를 명확하고 타입 안전하게 작성하려면 QueryDSL을 활용할 수 있습니다. JPQL로도 조인 쿼리를 작성할 수 있지만 앞서 말했듯 문자열 기반의 한계가 있습니다. QueryDSL은 자바 코드로 조인 조건을 명시하고
fetchJoin()등으로 N+1 문제를 피하는 등, 복잡한 조인 쿼리를 더 효과적으로 다루도록 돕습니다.
요약하면 이 문장은 “각 도구의 장점을 살려 적재적소에 활용하라”는 조언으로 받아들이는 게 현명합니다. 단순한 작업은
JpaRepository로 빠르게 처리하고, 복잡하고 동적인 조회는 QueryDSL의 강력한 기능으로 코드 품질을 높이는 전략입니다.
9. 연관관계를 끊는다는 의미
JPA에서 연관관계 매핑은 엔티티 간의 관계를 객체지향적으로 표현하는 핵심 기능입니다. 예를 들어 Order 엔티티가 Member 엔티티를 직접 참조하거나, Review 엔티티가 Product 엔티티를 직접 참조하는 방식입니다.
1
2
3
4
5
6
7
8
9
10
11
12
// 연관관계 매핑 예시
@Entity
public class Order {
@Id @GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member; // 주문이 회원을 직접 참조
// ...
}
반대로 연관관계를 끊는다는 것은, 엔티티 객체 자체를 직접 참조하는 대신 외래 키(FK) ID 값만 저장하는 방식을 말합니다. 객체 그래프 탐색으로 연관 엔티티에 접근하는 것을 포기하고, 필요하면 ID 값으로 직접 조회하거나 조인으로 데이터를 가져오는 방식이죠.
비유를 들어 설명해볼까요?
- 연관관계 매핑: 친구 객체(이름, 전화번호, 주소 등 모든 정보)를 내 연락처 앱에 통째로 연결해 둔 것과 같습니다. 친구의 모든 정보에 즉시 접근할 수 있죠.
- FK ID만 저장: 친구의 회원번호(ID)만 메모해 둔 것과 같습니다. 친구의 다른 정보가 필요하면 그 회원번호로 연락처 앱에서 다시 찾아봐야 합니다.
이 방식에는 다음과 같은 트레이드오프가 있습니다.
- 장점: 도메인 간의 결합도를 낮출 수 있습니다. 엔티티 간의 직접 참조가 줄어드니, 한 엔티티의 변경이 다른 엔티티에 미치는 영향을 최소화할 수 있죠. 특히 대규모 시스템이나 마이크로서비스 아키텍처에서 유용합니다.
- 단점: 객체 탐색(
order.getMember().getUsername())이 불가능해집니다. 연관된 데이터가 필요할 때는 해당 ID로 따로 조회하거나 쿼리에서 직접 조인해야 합니다. 개발의 편의성을 일부 희생하는 대신 시스템의 유연성과 확장성을 얻는 선택인 셈입니다.
어떤 방식을 고를지는 시스템의 요구사항, 성능, 유지보수성 등을 두루 따져 결정해야 합니다.
10. FK ID를 long으로 둘지 Long으로 둘지
JPA에서 외래 키(FK) ID를 다룰 때 long (primitive type)으로 선언할지, Long (wrapper type)으로 선언할지 고민할 때가 있습니다. 이 둘의 차이와 선택 기준을 분명히 알아두면 좋습니다.
long(primitive type):null값을 가질 수 없습니다. 초기화하지 않으면 기본값0이 할당되죠. 그래서0이 유효한 ID 값으로 쓰일 수 있는 상황에서는 “값이 없음”을 표현하기 어렵습니다.Long(wrapper type):null값을 가질 수 있습니다. “값이 없음”이나 “설정되지 않음” 상태를 분명하게 표현할 수 있습니다.
선택 기준:
| 상황 | 추천 |
|---|---|
| 생성 시 반드시 FK가 필요함 | long 가능 |
null 여부로 미설정 상태를 표현해야 함 | Long 권장 |
DB 컬럼이 nullable=false | long 또는 Long + 검증 |
| 요청 DTO에서 입력 누락 검증 필요 | Long 권장 |
- 생성 시 반드시 FK가 필요하고
null을 허용하지 않을 의도가 분명하다면long을 쓸 수 있습니다. 이 경우0이라는 기본값이 의미 있는 ID로 쓰이지 않도록 주의해야 합니다. - 요청 DTO처럼 입력 누락 검증이 필요한 경우에는
Long이 더 안전합니다.null여부로 사용자가 값을 입력했는지 분명히 판단할 수 있기 때문입니다. - DB 컬럼이
nullable=false라면Long을 쓰더라도 Bean Validation(@NotNull)이나 생성자 검증 등으로 필수값을 보장할 수 있습니다. 자바 코드 레벨에서null을 허용하더라도 데이터베이스 제약조건으로 무결성을 유지할 수 있죠.
이처럼 long과 Long 중 무엇을 고를지는 상황과 요구사항에 따라 달라집니다. “값이 없음”을 분명히 표현해야 하거나 유연한 처리가 필요하면 Long을, 성능을 최적화하거나 null이 불가능한 분명한 상황에서는 long을 고려해볼 수 있습니다.
글의 마무리
지금까지 QueryDSL을 학습하면서 헷갈렸던 개념들을 JPA와의 관계 속에서 정리해봤습니다. QueryDSL은 JPA를 대체하는 기술이 아니라, 기존 엔티티를 바탕으로 타입 안전하고 유연한 쿼리를 작성하게 해주는 강력한 도구라는 점을 다시 한번 강조하고 싶습니다.
JpaRepository와 QueryDSL은 경쟁 관계가 아니라, 각자의 강점을 살려 시너지를 내는 역할 분담 관계입니다. 단순 CRUD나 간단한 조회는 JpaRepository로 빠르게 처리하고, 복잡한 검색 조건이나 동적 쿼리, DTO 조회 등은 QueryDSL로 해결하는 것이 유지보수성과 코드 품질을 높이는 현명한 전략입니다.
연관관계 설계와 외래 키(FK) ID 관리 방식은 개발의 편의성과 도메인 간의 결합도 사이에서 트레이드오프를 따져 골라야 합니다. 정답은 없으며, 프로젝트의 특성과 요구사항에 맞춰 가장 적절한 방식을 찾아 적용하는 것이 중요합니다.
QueryDSL은 복잡한 데이터 조회 로직을 깔끔하고 효율적으로 작성하게 돕는 유용한 도구입니다. 이 글이 QueryDSL을 처음 접하거나 개념이 헷갈렸던 분들께 작은 도움이 되었기를 바랍니다.
오늘의 정리
QueryDSL은 JPA의 복잡한 조회 쿼리를 타입 안전하고 유연하게 작성하도록 돕는 보완재이며, JpaRepository와 역할 분담을 통해 코드 품질을 높일 수 있다.
연관관계 설계와 FK ID 타입 선택은 편의성과 결합도 사이의 트레이드오프를 고려해야 한다.