왜 컨테이너만으로는 부족할까?
들어가면서
이전 포스트들에서 VM과 컨테이너는 무엇이 다를까?, 컨테이너는 어떻게 격리될까?, Docker 이미지는 정말 OS일까?를 다루며 컨테이너의 개념과 격리 원리, 이미지의 본질을 살펴봤다. 컨테이너는 애플리케이션을 가볍게 패키징하고 실행하는 도구다.
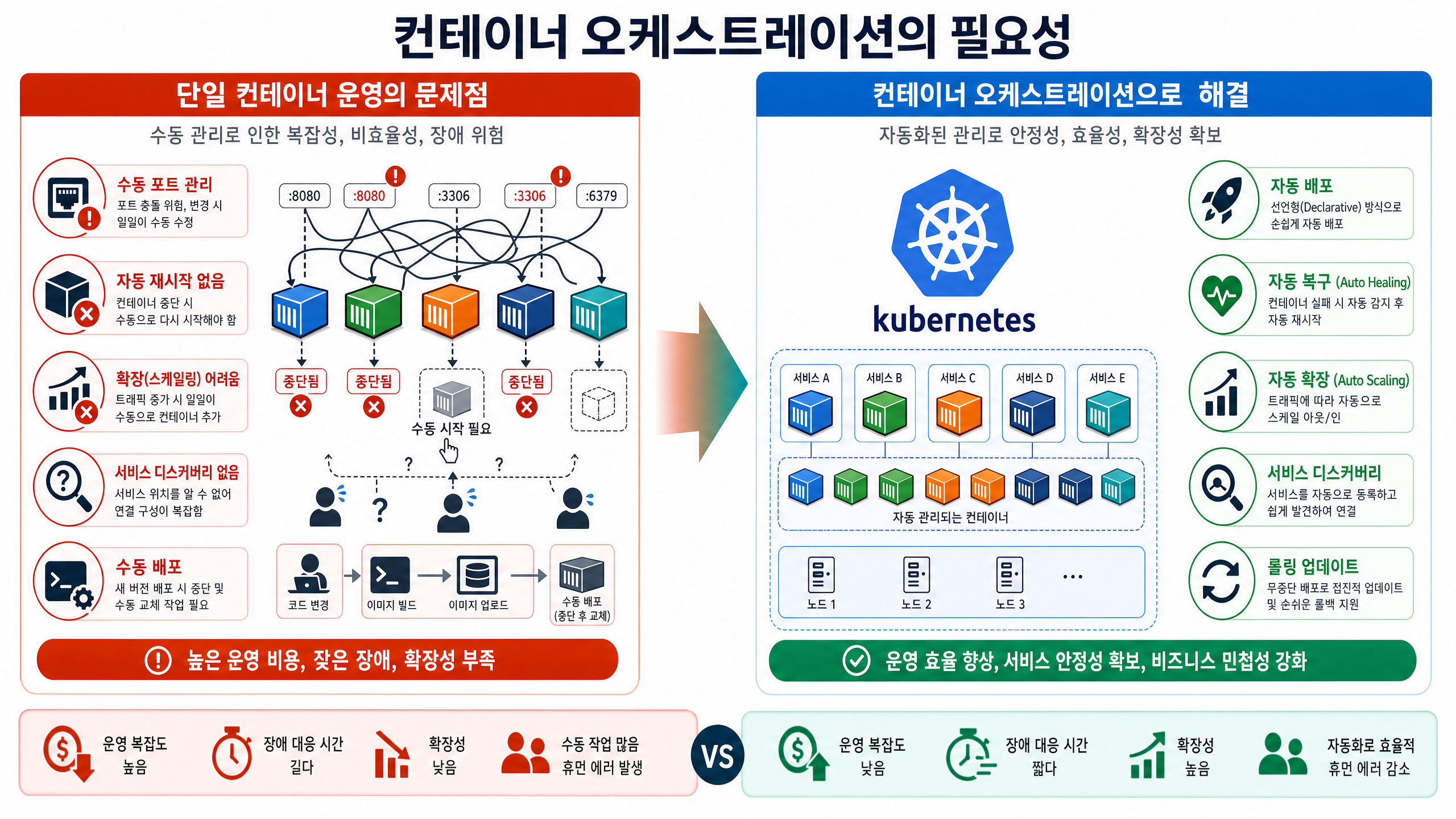
하지만 실제 운영 환경에서 수많은 컨테이너를 관리하는 것은 또 다른 문제다. docker run 명령 하나로 모든 운영 요구사항을 충족하기는 어렵다. 컨테이너 수가 늘고 서비스가 복잡해질수록 여러 문제가 드러난다. 이 글에서는 컨테이너 운영의 한계와 이를 극복하는 오케스트레이션의 필요성을 살펴본다.
이 글의 목표
- 컨테이너 운영의 한계를 이해한다.
- 오케스트레이션이 왜 필요한지 설명할 수 있다.
1. 단일 컨테이너는 쉽다
하나의 컨테이너를 실행하는 것은 매우 간단하다. docker run my-app과 같은 명령 하나로 애플리케이션을 격리된 환경에서 쉽게 구동할 수 있다. 개발 환경에서 특정 애플리케이션을 테스트하거나 간단한 유틸리티를 실행할 때는 이처럼 단일 컨테이너 방식이 매우 효율적이다.
2. 여러 컨테이너가 생기면?
하지만 실제 서비스가 단일 컨테이너로 구성되는 경우는 드물다. 웹 서버, 데이터베이스, 캐시, 백엔드 API 등 여러 컨테이너가 서로 연결되어 하나의 서비스를 이룬다. 컨테이너 수가 늘어나면 다음과 같은 문제에 부딪힌다.
- 포트 관리: 각 컨테이너가 사용하는 포트가 충돌하지 않도록 수동으로 관리해야 한다.
- 서비스 연결: 컨테이너 간 통신을 위해 IP 주소나 포트를 직접 연결해야 하며, 컨테이너가 재시작될 때마다 변경될 수 있는 IP를 추적해야 한다.
- 재시작: 컨테이너에 문제가 발생하여 중단되면, 이를 감지하고 수동으로 다시 시작해야 한다.
- 로그: 여러 컨테이너에서 발생하는 로그를 한곳에 모아 관리하고 분석하는 것이 어려워진다.
- 스케일링: 트래픽 증가에 따라 특정 컨테이너의 인스턴스를 늘리거나 줄이는 작업을 수동으로 해야 한다.
3. 운영에서 발생하는 문제
컨테이너 수가 많아지고 서비스가 복잡해질수록 위에서 언급한 문제는 더 심해지고 예측하기 어려운 운영 이슈로 이어진다.
장애 복구: 죽으면 누가 다시 띄우는가?
애플리케이션은 언제든 예기치 않은 오류로 중단될 수 있다. 컨테이너가 죽었을 때 이를 자동으로 감지하고 새 컨테이너를 띄워 서비스를 복구하는 메커니즘이 없다면 서비스는 오랜 시간 멈춘다. 안정성과 가용성에 직접 타격을 준다.
스케일링: 트래픽 증가 시 어떻게 늘릴까?
서비스의 인기가 많아져 트래픽이 급증하면, 기존 컨테이너만으로는 부하를 감당하기 어렵다. 이때 필요한 만큼 컨테이너 인스턴스를 자동으로 늘리고(Scale-out), 트래픽이 줄어들면 다시 줄이는(Scale-in) 유연한 스케일링 기능이 필요하다. 수동 스케일링은 비효율적이고 실시간 트래픽 변화에 대응하기 어렵다.
서비스 디스커버리: IP가 바뀌면 어떻게 찾을까?
컨테이너는 동적으로 생성되고 삭제되며, 이때마다 IP 주소가 변경될 수 있다. 다른 컨테이너나 외부 서비스가 특정 컨테이너를 찾아 통신해야 할 때, 변경되는 IP 주소를 어떻게 효율적으로 발견하고 연결할 수 있을까? 서비스 디스커버리 메커니즘 없이는 컨테이너 간의 안정적인 통신이 불가능하다.
배포 전략: 롤링 업데이트, 롤백
새로운 버전의 애플리케이션을 배포할 때, 기존 서비스를 중단하지 않고 점진적으로 업데이트하는 롤링 업데이트(Rolling Update)나, 문제가 발생했을 때 이전 버전으로 빠르게 되돌리는 롤백(Rollback) 기능은 필수적이다. 수동으로 컨테이너를 하나씩 교체하거나 이전 버전으로 되돌리는 것은 매우 번거롭고 오류가 나기 쉽다.
4. 오케스트레이션이란?
이러한 컨테이너 운영의 복잡성과 한계를 해결하려고 등장한 것이 컨테이너 오케스트레이션(Container Orchestration)이다. 오케스트레이션은 컨테이너화된 애플리케이션의 배포, 관리, 스케일링, 네트워킹, 로깅, 모니터링 등을 자동화하는 기술이다.
오케스트레이션의 핵심 목표는 “원하는 상태(Desired State) 유지”이다. 사용자가 정의한 애플리케이션의 상태(예: 특정 컨테이너 3개 실행, 특정 포트 사용, 특정 자원 할당 등)를 시스템이 지속적으로 감시하고, 현재 상태가 원하는 상태와 다를 경우 자동으로 조정하여 일치시킨다.
- 원하는 상태 유지: 사용자가 정의한 애플리케이션의 최종 상태를 항상 유지하려고 노력한다.
- 현재 상태 감시: 시스템의 현재 상태를 지속적으로 모니터링한다.
- 자동 복구: 컨테이너 장애 발생 시 자동으로 재시작하거나 다른 노드에 재배치하여 서비스를 복구한다.
5. Kubernetes로 연결
컨테이너 오케스트레이션 도구 중 가장 대표적인 것이 Kubernetes (쿠버네티스)이다. Google에서 시작되어 CNCF(Cloud Native Computing Foundation) 프로젝트로 발전한 Kubernetes는 복잡한 컨테이너 환경을 효율적으로 관리하기 위한 표준으로 자리 잡았다.
왜 Kubernetes가 등장했는가
Google은 내부적으로 수십억 개의 컨테이너를 관리하며 Borg라는 시스템을 개발하여 운영 효율성을 극대화했다. Kubernetes는 이러한 Borg의 경험과 노하우를 오픈소스로 공개한 결과물이다. 컨테이너 운영의 복잡성을 해결하고, 대규모 분산 시스템을 안정적으로 구축하기 위해 등장했다.
Kubernetes가 해결하는 문제
Kubernetes는 위에서 언급된 컨테이너 운영의 모든 문제점을 자동화된 방식으로 해결한다.
- 자동 배포 및 롤백: 선언적 방식으로 애플리케이션을 배포하고, 문제가 발생하면 자동으로 롤백한다.
- 자동 스케일링: 트래픽 부하에 따라 컨테이너 인스턴스를 자동으로 늘리거나 줄인다.
- 자체 복구: 실패한 컨테이너를 자동으로 재시작하고, 죽은 노드의 컨테이너를 다른 노드로 옮긴다.
- 서비스 디스커버리 및 로드 밸런싱: 컨테이너 간 통신을 위한 서비스 디스커버리를 제공하고, 트래픽을 여러 컨테이너로 분산한다.
- 스토리지 오케스트레이션: 영구 스토리지를 컨테이너에 자동으로 마운트한다.
- 시크릿 및 구성 관리: 민감한 정보(비밀번호, 토큰)와 애플리케이션 구성을 안전하게 관리한다.
6. 단일 컨테이너 vs 오케스트레이션 비교
컨테이너를 단일로 운영하는 방식과 오케스트레이션 도구를 사용하는 방식의 주요 차이점은 다음과 같다.
| 특징 | 단일 컨테이너 운영 | 컨테이너 오케스트레이션 (Kubernetes) |
|---|---|---|
| 관리 방식 | 수동 운영 | 자동 운영 (선언적) |
| 배포 | 수동 docker run | 자동화된 배포, 롤링 업데이트, 롤백 |
| 스케일링 | 수동 Scale-up/down | 자동 Scale-out/in |
| 장애 복구 | 수동 재시작 | 자동 감지 및 복구 |
| 서비스 디스커버리 | 수동 IP/Port 관리 | 자동 서비스 디스커버리, 로드 밸런싱 |
| 자원 관리 | 제한적 | CPU, Memory 등 자원 할당 및 제한 |
| 복잡성 | 낮음 (단일 앱) | 높음 (초기 설정 및 학습 곡선) |
| 가용성 | 낮음 | 높음 (고가용성, 무중단 서비스) |
마무리 정리
컨테이너는 애플리케이션 실행 환경을 표준화하고 개발-배포 과정을 간소화했다. 하지만 단일 컨테이너만으로는 복잡한 분산 시스템의 운영 요구사항을 충족하기 어렵다.
- 컨테이너는 실행 단위를 표준화하고,
- 오케스트레이션은 운영을 자동화한다.
컨테이너와 오케스트레이션은 서로 보완하는 관계다. 둘을 함께 쓸 때 클라우드 네이티브 애플리케이션의 가치가 제대로 드러난다. 프로젝트 규모와 복잡성에 맞춰 적절한 오케스트레이션 도구를 선택하고 활용하는 것이 중요하다.