실전 클라우드 배포와 운영: 내가 마주한 기술적 고민과 해결책
들어가면서
최근 클라우드 환경에서 프로젝트를 진행하면서 기술적인 고민도 많았고 예상 못 한 문제도 여러 번 겪었다. 기능을 구현하는 것과 실제 운영 환경에서 안정적으로 돌아가게 만드는 것은 다른 문제였고, 그 차이를 메우는 과정에서 배운 게 많았다.
이 글에는 클라우드 환경(AWS EC2, RDS, S3, ALB 등)에 애플리케이션을 배포하고 운영하면서 마주친 트러블슈팅 사례를 정리했다. 각 사례마다 원인이 무엇이었고 어떤 고민 끝에 해결했는지 기록했다.
이 글의 목표
- 클라우드 환경에서의 배포 및 운영 시 발생할 수 있는 실제 문제들을 이해한다.
- 각 문제에 대한 해결 과정과 기술적 배경을 파악한다.
- 운영 환경에서의 디버깅 및 문제 해결 능력을 향상시키는 데 도움을 얻는다.
1. ID 전략 및 데이터 설계 고민
UUID를 사용한 이유
이번 프로젝트에서는 회원 ID를 Long Auto Increment 방식 대신 UUID 기반으로 구현했다. 일반적인 CRUD 프로젝트에서는 Long 기반의 Auto Increment ID가 단순하고 인덱스 성능 측면에서 유리하지만, 이번 과제는 단순 로컬 애플리케이션이 아닌 EC2, RDS, S3, ALB, ASG, CloudFront 등을 사용하는 클라우드 기반 환경이었기 때문에 확장 가능한 구조를 고려해야 했다.
UUID를 사용하면 애플리케이션 레벨에서 고유 ID를 생성할 수 있어, 여러 서버 인스턴스가 동시에 데이터를 생성하더라도 ID 충돌 가능성을 낮출 수 있다. 또한 Auto Increment 기반의 Long ID는 /api/members/1, /api/members/2처럼 데이터 생성 순서가 외부에 노출되어 다음과 같은 문제가 발생할 수 있다.
- 전체 데이터 규모 추측 가능
- 생성 순서 노출
- 다른 리소스 ID 예측 가능
반면 UUID는 예측이 어려운 랜덤 식별자이므로 외부 API 리소스 식별자로 더 적절하다고 판단했다.
UUID 저장 방식: BINARY(16) vs CHAR(36)
UUID 저장 방식은 BINARY(16)이 아닌 CHAR(36) 기반 문자열 형태로 저장했다. 일반적으로 UUID는 BINARY(16)과 CHAR(36) 두 가지 방식으로 많이 저장된다.
BINARY(16) 방식은 저장 공간과 인덱스 효율 측면에서 유리하지만, 실제 DB에서 값을 직접 조회했을 때 사람이 읽기 어렵다는 단점이 있다. 반면 CHAR(36) 방식은 저장 공간을 조금 더 사용하지만 다음과 같은 장점이 있다.
- DB 조회 시 가독성 확보
- 로그 분석 편의성
- 운영 중 디버깅 용이성
- UUID 값을 바로 확인 가능
이번 프로젝트는 대규모 트래픽 최적화보다는 클라우드 인프라 구성, 운영 환경 경험, 장애 분석 및 디버깅, AWS 기반 배포 구조 이해에 더 초점이 있었기 때문에, 운영 중 가독성과 디버깅 편의성을 우선하여 CHAR(36) 기반 문자열 저장 방식을 선택했다.
다만 UUID는 Long보다 저장 공간 사용량 증가, 인덱스 성능 저하 가능성, 정렬 비효율 등의 단점도 존재함을 인지하고 사용해야 한다.
2. 유지보수성 고려: 에러 코드를 도메인별로 분리한 이유
이전 팀 프로젝트에서는 모든 에러 코드를 하나의 ErrorCode에서 관리했다. 처음에는 공통 에러 코드를 한 곳에서 관리하면 에러 정책 통일, 공통 관리 용이성, 전체 에러 흐름 파악 측면에서 유지보수에 더 좋다고 생각했다.
하지만 프로젝트 규모가 커지고 여러 팀원이 동시에 작업하게 되면서 예상치 못한 문제가 발생했다. 각 도메인에서 초기에 정의하지 못했던 새로운 에러 코드들이 계속 추가되었고, 그 과정에서 여러 사람이 동일한 ErrorCode 파일을 수정하게 되어 Git 충돌이 자주 발생했다.
특히 Member, Auth, 주문, 파일 업로드 관련 에러 등이 하나의 파일에 계속 누적되면서 파일 크기 증가, 도메인 경계 모호화, 유지보수성 저하, 필요한 에러 탐색 어려움 문제도 함께 발생했다.
이 경험을 바탕으로 이번 프로젝트에서는 이러한 문제를 미리 방지하기 위해 처음부터 도메인별 에러 코드 분리를 고려했다. 현재는 MemberErrorCode를 별도로 분리하여 관리하고 있으며, 이후에는 AuthErrorCode, StorageErrorCode처럼 다른 도메인들도 동일한 방식으로 분리하는 방향을 고려하고 있다. 이렇게 하면 Git 충돌 감소, 도메인 책임 분리, 에러 관리 가독성 향상, 유지보수성 개선 효과를 기대할 수 있다.
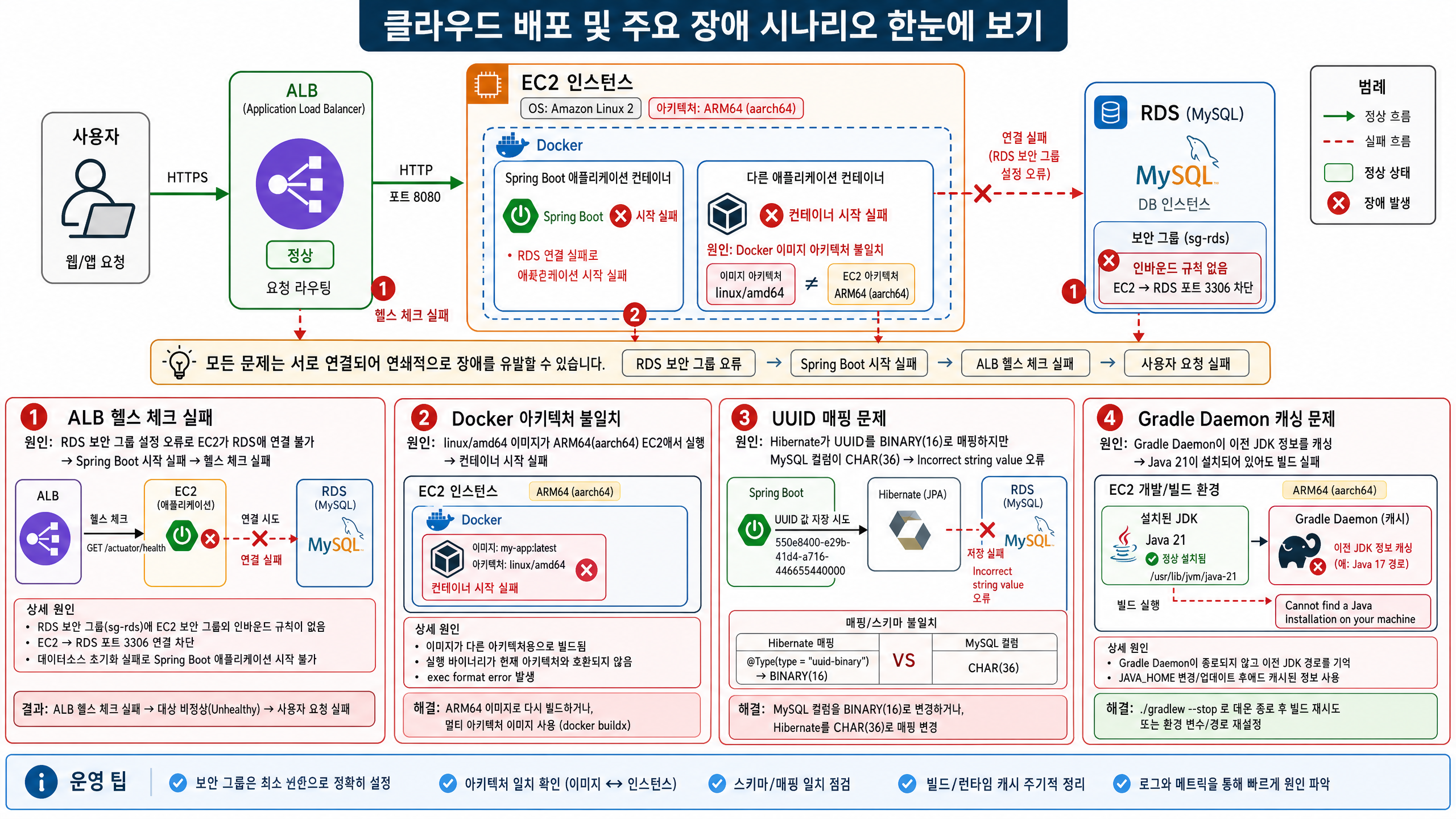
3. 인프라 및 배포 트러블슈팅
클라우드 환경에 배포하면 로컬에서는 없던 문제들이 겹쳐서 터진다. 실제로 운영하면서 마주친 사례들을 정리했다.
3.1. 로컬은 정상, 운영(RDS)에서는 실패: Hibernate 7 UUID 문제
회원 생성 API가 로컬(H2)에서는 정상 동작했지만, AWS RDS(MySQL) 환경에서만 실패하는 문제가 발생했다. 처음에는 UTF-8이나 charset 문제를 의심했지만, 실제 원인은 Hibernate 7의 UUID 저장 전략과 MySQL 컬럼 타입 불일치였다.
1
2
3
@Id
@Column(columnDefinition = "CHAR(36)")
private UUID id;
DB는 CHAR(36) 문자열 저장을 기대했지만, Hibernate는 UUID를 내부적으로 BINARY(16) 기반으로 처리하려고 했다. 결과적으로 H2에서는 관대하게 동작했지만, MySQL에서는 Incorrect string value 에러가 발생했다.
이 문제를 겪으면서 “로컬에서 되니까 괜찮다”는 식으로 넘길 게 아니라 Hibernate 기본 매핑 전략, DB Dialect 차이, 실제 운영 DB가 어떻게 동작하는지까지 봐야 한다는 걸 알았다. 그 뒤로는 되도록 운영과 비슷한 환경에서 테스트하려고 한다.
3.2. Gradle Daemon 때문에 발생했던 Java 21 인식 문제
EC2에서 Spring Boot 프로젝트를 빌드하는 과정에서 Cannot find a Java installation on your machine matching: {languageVersion=21} 에러가 발생했다. 처음에는 단순히 Java 21이 설치되지 않은 문제라고 생각했지만, 실제로는 Java 21 설치가 완료되었고 javac도 정상 동작하는 상태였다.
원인은 Gradle Daemon이 이전 JDK 환경 정보를 캐싱하고 있었기 때문이었다. ./gradlew --stop 명령으로 Daemon을 재시작한 뒤 ./gradlew clean build를 수행하자 정상적으로 해결되었다. 덕분에 java -version만 볼 게 아니라 javac -version까지 확인해야 한다는 것도 알게 됐다.
3.3. Docker는 “어디서든 실행된다”가 아니라 아키텍처도 맞아야 한다는 점
GitHub Actions 기반 CI/CD를 구축한 뒤, Docker 이미지는 정상적으로 배포되었지만 EC2에서 컨테이너가 계속 재시작되는 문제가 있었다. 로그를 확인해보니 exec /opt/java/openjdk/bin/java: exec format error가 발생하고 있었다.
원인은 GitHub Actions 환경(linux/amd64)과 EC2 환경(ARM64(aarch64)) 간의 아키텍처 불일치였다. 처음에는 Spring 설정이나 환경 변수 문제를 의심했지만, 실제로는 Docker 이미지 자체의 플랫폼 차이 문제였다.
이후 GitHub Actions에서 platforms: linux/arm64로 빌드 플랫폼을 명시해 해결했다. 이 일로 EC2 인스턴스 타입과 CPU 아키텍처, Docker 빌드 플랫폼이 서로 맞아떨어져야 한다는 걸 알았다. CI/CD를 짤 때 실행 환경까지 신경 써야 한다는 것도 이때 배웠다.
3.4. ALB Target Group이 Unhealthy였던 원인
ALB Health Check가 계속 실패해서 처음에는 Spring Boot 설정 문제, Actuator 설정 문제, 컨테이너 문제 등을 의심했다. 하지만 실제 원인은 애플리케이션 자체가 아니라 EC2와 RDS 간의 연결 실패, 즉 RDS Security Group 설정 오류였다.
Private EC2 SG → RDS SG : 3306 허용 구조가 되어야 했는데, RDS가 다른 Security Group을 허용하고 있었다. 결국 Spring Boot 부팅 실패, Hibernate Dialect 초기화 실패, /actuator/health 실패, ALB Target Group Unhealthy까지 연쇄적으로 발생했다.
RDS 인바운드 규칙을 현재 EC2 Security Group 기준으로 고치자 해결됐다. 겉으로는 “ALB가 문제다” 싶었지만, 실제로는 네트워크 구조와 Security Group 체이닝, 애플리케이션 부팅 의존성까지 얽혀 있었다.
4. 파일 업로드 API를 구현하면서 HTTP Multipart 구조를 이해하게 된 점
프로필 이미지 업로드 API를 만들 때 처음에는 @RequestParam MultipartFile만 떠올렸다. 그런데 파일 업로드는 multipart/form-data 구조라서 요청 내부가 여러 개의 part로 나뉜다는 걸 알게 됐다.
그래서 이후에는 @RequestPart("image") MultipartFile image 형태로 명확하게 처리했다. 특히 JSON과 파일을 함께 올리는 구조까지 생각하면, 의미도 분명하고 유지보수나 요청 구조 면에서도 @RequestPart가 더 낫다고 봤다.
마무리 정리
클라우드에서 개발하고 운영하다 보니, 코드를 짜고 배포하는 것만으로는 부족했다. 인프라와 네트워크, 배포 파이프라인까지 어느 정도 알아야 문제가 풀렸다. 로컬에서는 그냥 넘어가던 것들이 운영에서는 큰 장애로 번지는 일도 여러 번 겪었다.
이런 경험을 거치면서 개별 기술만이 아니라 문제를 여러 각도에서 보고 시스템 전체를 살피는 눈이 조금씩 생겼다. 앞으로도 계속 부딪쳐 가며 익혀 나가려 한다.